K6の負荷テスト結果をGrafana+InfluxDBで可視化する
はじめに
K6は実行結果を様々なプラットフォームに送信して可視化することが可能です。
その中の選択肢としてGrafana+InfluxDBを利用することが可能なようなので、試してみたいと思います。
このブログでは、それぞれのツールはDockerを利用して立ち上げることを想定しています。公式のdocker-composeを用意されていますが今回は利用せずにやってみようと思います。
また、今回使うK6のスクリプトは以前のブログで最後に作成したものを利用しようと思います。簡単にまとめると10のVUsで一秒間の1回10秒リクエストを送るスクリプトを使います。また、テスト対象のアプリも同様に以前のブログで利用したものを利用します。helloの文字列を返すだけのAPIです。
やってみる
動作環境
$ lsb_release -a LSB Version: core-11.1.0ubuntu2-noarch:security-11.1.0ubuntu2-noarch Distributor ID: Ubuntu Description: Ubuntu 20.04.1 LTS Release: 20.04 Codename: focal $ uname -srvmpio Linux 5.4.0-58-generic #64-Ubuntu SMP Wed Dec 9 08:16:25 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux $ docker version Client: Docker Engine - Community Version: 19.03.12 API version: 1.40 Go version: go1.13.10 Git commit: 48a66213fe Built: Mon Jun 22 15:45:36 2020 OS/Arch: linux/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 19.03.12 API version: 1.40 (minimum version 1.12) Go version: go1.13.10 Git commit: 48a66213fe Built: Mon Jun 22 15:44:07 2020 OS/Arch: linux/amd64 Experimental: true containerd: Version: 1.2.13 GitCommit: 7ad184331fa3e55e52b890ea95e65ba581ae3429 runc: Version: 1.0.0-rc10 GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd docker-init: Version: 0.18.0 GitCommit: fec3683
InfluxDB を立ち上げる
最初に、諸々適当なDockerのネットワークを作成しておきます。
$ docker network create k6net
まずは、InfluxDBを立ち上げます。
InfluxDBは公式のイメージを利用して立ち上げます。
データの永続化の問題もありますが、今回は試したいだけなので、ボリュームを当てたりはしません。
$ docker run --network k6net --name influxdb -d influxdb
K6の実行結果をInfluxDBに保存する
InfluxDBが立ち上がったところで早速テストを実行していきたいと思います。
あたらためて書くと今回利用するスクリプトとアプリは以前のブログで利用したものを再利用します。
K6でテストを行ってその実行結果をInfluxDBに送信するには次のコマンドを実行します。
$ docker run --rm --network k6net -i loadimpact/k6 run --out influxdb=http://influxdb:8086/k6db - < k6script.js
ここで重要なのは--out influxdb=http://influxdb:8086/k6dbのところです。K6では様々なOUTPUTのプラグイン が用意されており、--outの引数に指定するだけで簡単に測定結果を送信することができます。
スクリプトの実行が完了されると、InfluxDBにk6dbという名前でDBが作成されます。
Grafanaでデータを可視化する
ここまででInfluxDBにテスト結果の格納することまでができたので、最後にその可視化を行っていきます。
まずは、Grafanaを立ち上げます以下のコマンドを叩きます。
docker run --network=k6net -d -p 3000:3000 grafana/grafana
起動するとlocalhost:3000でアクセスすることができます。

初回、ユーザ/パスワードはadmin/adminです。
次にInfluxDBを起動します。
$ docker run --name influxdb quay.io/influxdb/influxdb:v2.0.3
Grafanaがたち上がったら、InfluxDBと連携させます。
Grafanaのサイドウィンドウから、[歯車]⇨[Add Data Source]を選択し、サーチボックスにInfluxDBと入力してInfluxDBの項目を選択します。

設定は以下のように入力します。

Databaseの項目はK6の実行の際に作成されたものを利用します。
これで連携は完了です。
あとはいい感じにダッシュボードを作成すればよいです。
(ちなみに以下の画像はk6 Load Testing Resultsのテンプレートを利用してます)

InfluxDBのオプション
スクリプト実行時のInfluxDBに対するオプションがいくつかあるので以下にまとめます。 オプションは実行時の環境変数として設定することで利用することができます。
| 環境変数 | 説明 |
|---|---|
| K6_INFLUXDB_USERNAME | InfluxDBのユーザネーム |
| K6_INFLUXDB_PASSWORD | InfluxDBのパスワード |
| K6_INFLUXDB_INSECURE | tureになってる場合httpsの証明書検証をスキップする |
| K6_INFLUXDB_TAGS_AS_FIELDS | K6のメトリクスの中で、インデックスできないフィールドをコンマ区切りで指定する。オプションでインデックスのvu:intのように型を指定できる。方はint、bool、float、stringがある |
参考資料
負荷テストツールK6を試す
はじめに
負荷テストのツールを何かしら勉強したいなと思って、K6というツールがあるというのを知って良さそうに感じたのでとりあえず動かしてみるところまでやってみようと思います。
K6とは
K6はLoad Impactという負荷テストのサービスを作っていた会社が、その経験を活かして作ったOSSみたいです。その機能に以下のようなものがあります。
- ES6でのスクリプティング
- テストも設定オプションもJSのコードで記述できる
- CIでの自動化サポート(アサーションや成功/失敗を判定するしきい値の設定が可能)
- HTTP/1.1、2、WebSocket、gRPCのサポート
- TLS機能のサポート
- ビルドインのHARコンバーター
- InfluxDB (+Grafana)やJson等を利用したメトリクスの公開
- その他様々な機能
- クッキー
- 暗号化
- メトリクスのカスタマイズ
- エンコーディング
- HTMLフォーム
Virtual User
K6にはVirtual Users(VUs)という概念があります。
Virtual Usersはそれぞれが分けられた環境で、並行でテストスクリプトを実行してくれます。
また、Virtual Userはリアルユーザの真似をするようなリクエストを送ることも可能みたいです。
使ってみる
早速使ってみたいと思います。
K6を実行するためにはそのツールセットをインストールする必要がありますが今回はDockerを利用してK6を実行したいと思います。
環境
実行環境は以下の通りです。
$ uname -srvmpio Linux 5.4.0-58-generic #64-Ubuntu SMP Wed Dec 9 08:16:25 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux $ lsb_release -a LSB Version: core-11.1.0ubuntu2-noarch:security-11.1.0ubuntu2-noarch Distributor ID: Ubuntu Description: Ubuntu 20.04.1 LTS Release: 20.04 Codename: focal $ docker version Client: Docker Engine - Community Version: 19.03.12 API version: 1.40 Go version: go1.13.10 Git commit: 48a66213fe Built: Mon Jun 22 15:45:36 2020 OS/Arch: linux/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 19.03.12 API version: 1.40 (minimum version 1.12) Go version: go1.13.10 Git commit: 48a66213fe Built: Mon Jun 22 15:44:07 2020 OS/Arch: linux/amd64 Experimental: true containerd: Version: 1.2.13 GitCommit: 7ad184331fa3e55e52b890ea95e65ba581ae3429 runc: Version: 1.0.0-rc10 GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd docker-init: Version: 0.18.0 GitCommit: fec3683
事前準備
インストール
前述の通り、K6を実行するにはそのツールセットをインストールする必要があります。様々な環境でインストール、動作させることが可能です。
Linux(Ubuntu/Debian)
DabianベースのLinuxの場合はプライベートのdebリポジトリからインストールすることができます。
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 379CE192D401AB61 echo "deb https://dl.bintray.com/loadimpact/deb stable main" | sudo tee -a /etc/apt/sources.list sudo apt-get update sudo apt-get install k6
Docker
Dockerイメージloadimpact/k6が公開されており、そのイメージを用いたテストの実行も可能です。
docker pull loadimpact/k6
Mac
Macではbrewを使ってインストールすることができるみたいです。
brew install k6
バイナリでのインストール
GitHubのページからバイナリを取得することも可能です。
リンクからバイナリをダウンロードしてPATHを通して通してください。
テストするアプリを用意する
インストールが終わったところで、テスト対象のアプリを準備しておきます。
今回は環境が用意できればなんでもよいので個人的に1番使い慣れてるSpringを使ってアプリを作ろうと思います。
Spring Initializrを使ってアプリを作成します。
設定は以下のように

出来上がったプロジェクトをエディタ等で開き作成されているApplicationクラスを以下のように修正します。
@SpringBootApplication @RestController public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } @GetMapping("/hello") public String hello(){ return "hello"; } }
アプリを起動してcURLでエンドポイントへアクセスするとHelloという文字列が返ってきます。
$ curl localhost:8080/hello hello
テストコードを書く
それでは準備ができたところで実際にテストスクリプトを書いて行きたいと思います。 K6でスクリプトを記述する場合基本的なスクリプトの構成は以下のようになります。
// init code export default function() { // vu code }
K6ではdefalt functionを定義してやる必要があり、これが一般的に言うメイン関数のようなテストコードのエントリーポイントとなります。
defalt functionの中のコードのことをVU codeと呼び、外側のコードのことをinit codeと呼びます。
ここで、Virtual Usersを利用して、並行化されるのはVU codeであり、init codeは一回のみ実行されます。VU codeの中ではHTTPなどのリクエストを送信しそのメトリクスを計測することは可能ですが、ローカルのファイルシステムを読み込んだり、他のモジュールを呼んだりすることはできません。それらはinit codeで実行することが必要です。
以上のことを踏まえて、リクエストを一回実行して1秒だけまつスクリプトを記述します。
k6script.js
import http from 'k6/http'; import { sleep } from 'k6'; export default function () { http.get('http://${HOST_IP}:8080/hello'); sleep(1); }
テストコードが記述できたので早速実行してみます。 実行は以下のようにコマンドを叩きます。
$ docker run -i loadimpact/k6 run - < ${SCRIPT_NAME}.js
今回の場合は次のようになります。
$ docker run -i loadimpact/k6 run - < k6script.js
/\ |‾‾| /‾‾/ /‾‾/
/\ / \ | |/ / / /
/ \/ \ | ( / ‾‾\
/ \ | |\ \ | (‾) |
/ __________ \ |__| \__\ \_____/ .io
execution: local
script: -
output: -
scenarios: (100.00%) 1 scenario, 1 max VUs, 10m30s max duration (incl. graceful stop):
* default: 1 iterations for each of 1 VUs (maxDuration: 10m0s, gracefulStop: 30s)
running (00m01.0s), 1/1 VUs, 0 complete and 0 interrupted iterations
default [ 0% ] 1 VUs 00m01.0s/10m0s 0/1 iters, 1 per VU
running (00m01.0s), 0/1 VUs, 1 complete and 0 interrupted iterations
default ✓ [ 100% ] 1 VUs 00m01.0s/10m0s 1/1 iters, 1 per VU
data_received..............: 118 B 114 B/s
data_sent..................: 89 B 86 B/s
http_req_blocked...........: avg=1.67ms min=1.67ms med=1.67ms max=1.67ms p(90)=1.67ms p(95)=1.67ms
http_req_connecting........: avg=1.61ms min=1.61ms med=1.61ms max=1.61ms p(90)=1.61ms p(95)=1.61ms
http_req_duration..........: avg=2ms min=2ms med=2ms max=2ms p(90)=2ms p(95)=2ms
http_req_receiving.........: avg=83.92µs min=83.92µs med=83.92µs max=83.92µs p(90)=83.92µs p(95)=83.92µs
http_req_sending...........: avg=72.25µs min=72.25µs med=72.25µs max=72.25µs p(90)=72.25µs p(95)=72.25µs
http_req_tls_handshaking...: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...........: avg=1.84ms min=1.84ms med=1.84ms max=1.84ms p(90)=1.84ms p(95)=1.84ms
http_reqs..................: 1 0.96781/s
iteration_duration.........: avg=1s min=1s med=1s max=1s p(90)=1s p(95)=1s
iterations.................: 1 0.96781/s
vus........................: 1 min=1 max=1
vus_max....................: 1 min=1 max=1
コンソールに実行結果が出力されているのがわかります。
ちょっとだけ細かく見てみると、送信したデータ量(B/s)、受信したデータ量(B/s)、リクエストでブロックされた時間、接続にかかった時間、等々の平均値やパーセントタイルの値などが表示されていますね。
VirtualUsersを追加して、テストの実行時間を変更する
次に、Virtual Usersを追加してリクエストを並行で送ってみるようにしてみたいと思います。 方法は以下の4つほどあります
- テスト実行時オプション(
--vusand-duration)として渡す - 環境変数として定義しておく
.jsonの設定ファイルを作成し、実行時に読み込ませるinit callにoptionsのJsonオブジェクトを定義する
今回は4つ目のJsonオブジェクトを定義する方でやろうと思います。
具体的には、「10 users で10秒間リクエストを送る」ように、先程のコードを以下のように書き換えます。
import http from 'k6/http'; import { sleep } from 'k6'; export let options = { vus: 10, duration: '10s', }; export default function () { http.get('http://${HOST_IP}:8080/hello'); sleep(1); }
option.vusとoption.durationをそれぞれinit codeの領域で設定しています。
テストを実行すると先ほどと違って、10並行で、10秒間リクエストが送られていることがわかります。
$ docker run -i loadimpact/k6 run - < k6script.js
/\ |‾‾| /‾‾/ /‾‾/
/\ / \ | |/ / / /
/ \/ \ | ( / ‾‾\
/ \ | |\ \ | (‾) |
/ __________ \ |__| \__\ \_____/ .io
execution: local
script: -
output: -
scenarios: (100.00%) 1 scenario, 10 max VUs, 40s max duration (incl. graceful stop):
* default: 10 looping VUs for 10s (gracefulStop: 30s)
running (01.0s), 10/10 VUs, 0 complete and 0 interrupted iterations
default [ 9% ] 10 VUs 00.9s/10s
running (02.0s), 10/10 VUs, 10 complete and 0 interrupted iterations
default [ 19% ] 10 VUs 01.9s/10s
(略)
default [ 99% ] 10 VUs 09.9s/10s
running (10.1s), 00/10 VUs, 100 complete and 0 interrupted iterations
default ✓ [ 100% ] 10 VUs 10s
data_received..............: 12 kB 1.2 kB/s
data_sent..................: 8.9 kB 880 B/s
http_req_blocked...........: avg=32.42µs min=2.11µs med=11.88µs max=855.09µs p(90)=49.84µs p(95)=172.34µs
http_req_connecting........: avg=19.37µs min=0s med=0s max=814.16µs p(90)=4.29µs p(95)=144.09µs
http_req_duration..........: avg=3.67ms min=704.32µs med=3.94ms max=8.48ms p(90)=6.71ms p(95)=7.35ms
http_req_receiving.........: avg=99.37µs min=16.55µs med=103.15µs max=223.89µs p(90)=173.99µs p(95)=182.34µs
http_req_sending...........: avg=49.94µs min=9.15µs med=47.83µs max=334.41µs p(90)=70.58µs p(95)=87.42µs
http_req_tls_handshaking...: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...........: avg=3.52ms min=658.68µs med=3.75ms max=8.3ms p(90)=6.52ms p(95)=6.92ms
http_reqs..................: 100 9.895886/s
iteration_duration.........: avg=1s min=1s med=1s max=1s p(90)=1s p(95)=1s
iterations.................: 100 9.895886/s
vus........................: 10 min=10 max=10
ここまでで、ざっくりとK6の利用方法は把握できた気がします。
テスト結果の出力
テスト結果はデフォルトではコンソールに出力されますが、以下のような出力先を変更するプラグインがいくつか用意されています。
この他にもNew Relicなどもあります。
オプション
最後に、その他にどんなことができるのかざっくり把握するためオプションで気になったところをいくつかまとめたいと思います。
全量はここで確認することができます。
Duration
Durationでは、テストが実行される時間を設定することができます。
実行時間中はそれぞれのVUsでスクリプトがループして呼ばれ続けます。
例えば以下のような設定の場合3分間vu codeがループで実行され続けます。
export let options = { duration: '3m', };
Iterations
IterationsオプションはVUsがそれぞれ何度スクリプトを実行するかを指定することができます。
この値は、VUsで単純に割り算され、例えば以下のような設定である場合10Vusがそれぞれ10回のリクエストを実行します。
export let options = { vus: 10, iterations: 100, };
No VU Connection Reuse
No VU Connection ReuseではTCPをVUsの実行の中でTCPコネクションを再利用するかをbooleanで設定できます。 設定は以下のように行います。
export let options = { noVUConnectionReuse: true, };
RPS
RPSではVUsをまたいだ秒間での最大リクエスト数を設定することができます。
export let options = { rps: 500, };
Scenarios
Scenariosでは、1つ以上の実行パターンを定義することができます。シナリオは以下のような特徴があります。
- 同じスクリプトに対して複数のシナリオを定義できる
- それぞれのシナリオは個別のVUsやスケジュールパターンを持つことができる
- それぞれのシナリオは直列でも並行でも実行することができる
- シナリオごとに違った環境変数やメトリクスタグをセットすることができる
より詳細な情報はこちらを参考にしてください。
利用イメージは以下のようになります。
export let options = { scenarios: { my_api_scenario: { // arbitrary scenario name executor: 'ramping-vus', startVUs: 0, stages: [ { duration: '5s', target: 100 }, { duration: '5s', target: 0 }, ], gracefulRampDown: '10s', env: { MYVAR: 'example' }, tags: { my_tag: 'example' }, }, }, };
Stages
StagesではVUsの上昇や下降を制御することができます。
例えば以下のような設定の場合、最初の3分間でVUsを1から10まで上昇させ5分間そのままリクエストを続けその他とに10から35ユーザ10分間で増やしていき、最後の3分でVUsを0まで減らします。
export let options = { stages: [ { duration: '3m', target: 10 }, { duration: '5m', target: 10 }, { duration: '10m', target: 35 }, { duration: '3m', target: 0 }, ], };
参考資料
Nettyの主要コンポーネントを整理する
はじめに
Nettyを勉強していると、EventLoopやHandlerなど様々なコンポーネントがでてきて、混乱したのでちょっと図でまとめてみようと思います。このブログでは以下のようなNettyの主要コンポーネント(クラス or インターフェース)の役割をまとめそれぞれの関係を図で整理しようと思います。
- EventLoop、EventLoopGroupe
- Channel
- ChannelHandler、ChannelPipeline
Netty In Actionなどの書籍を参考にしていますが、あくまで自分の理解をまとめますので、正しい理解を行いたい場合は書籍やドキュメント実装を当たるようにしてください。
非同期I/O? 同期I/O?
前提としてJavaのネットワーク通信における、同期I/Oと非同期I/Oについてちょっと整理してみようと思います。
Javaにおけるネットワーキングプログラムは、はじめ、ネイティブのソケットライブラリーを使った同期的なAPI(java.net)が用意されていました。その、同期的なAPIを使った複数通信を扱う際のイメージは以下のようになります。
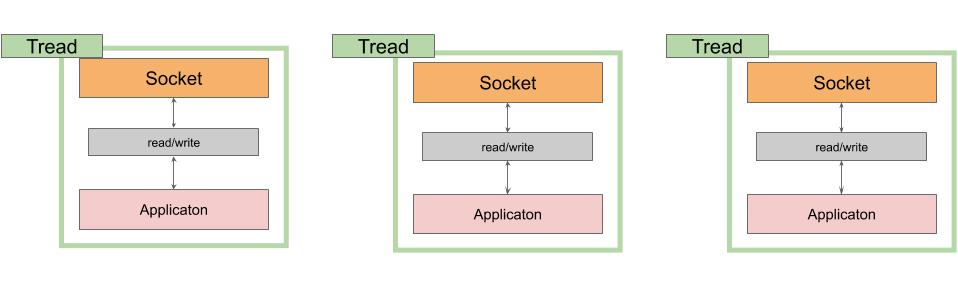
このような同期I/Oでは、ソケットごとにスレッドが作成され、それらのスレッドはI/Oオペレーションを行っている間はスレッドは休眠状態に入ります。そうなるとリソースの無駄が発生してしまいます。更に、それぞれのスレッドはOSによって決められたサイズのメモリを確保しますのでそうったオーバーヘッドも発生してしまいます。
上記のような同期I/Oに対して、Java 1.4らNIO(java.nio)が導入されました。NIOでは、システムのイベント通知APIを用いて、データの読み取りや書き取りが行われたことを通知を受けることで、非同期的な通信を可能としています。
NIOを用いたJavaにおけるネットワーク通信は以下のようになります。
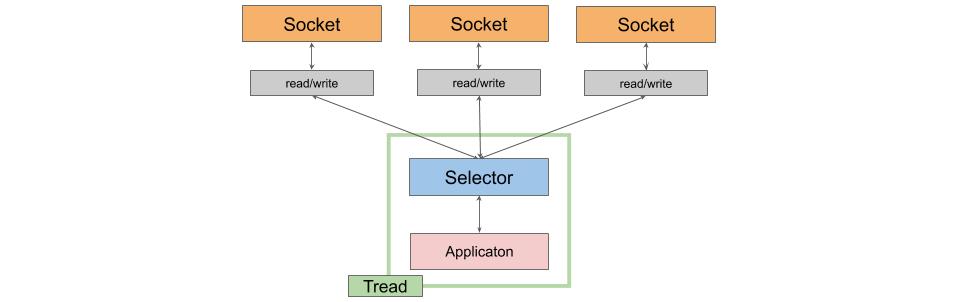
class java.nio.channels.Selectorは複数の非同期ソケットが処理可能な状態にあるかのイベント通知を受け、ハンドリングします。同期IOに比べソケットに対して、1つだけののスレッドが割り当てられているため、コンテクストスイッチなどにおける、CPUリソースの無駄遣いの削減や、メモリ消費の削減に繋がり、また、スレッドも休眠せずI/O待ちの際に別のタスクを消費することができます。
Nettyとは
NettyはJavaのNIOの上に作られるネットワークアプリケーションを作るためのフレームワークです。NIOを直接使うよりも、より簡単にすばやくアプリケーションの開発を行なうことができます。また、プーリングと再利用によってJavaのAPIを直接使うよりも低いレイテンシ、高スループットを実現してします。
NettyはNIO以外のライブラリー等には依存しておらず、3.x系ならJava 5、4.x系ならJava 6以上(一部、オプションの機能を利用する場合は7以上が求められます)で動きます。
ちなみにNIOに対して、同期的I/OをNettyではOIOと呼んでいるようです。
Nettyのコンポーネントと全体像
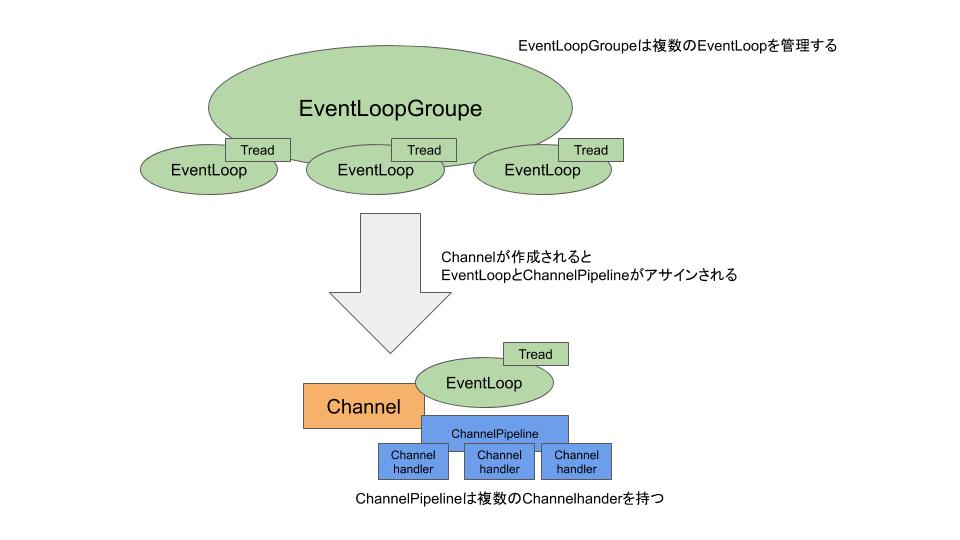
Nettyの主要コンポーネントを一枚の図のような関係になります。 以降でそれぞれのコンポーネントについて見ていきたいと思います。
Channel
まず、NettyのChannelについてですが、これは、Socketを直接使う場合の複雑さを削減するためのコンポーネントで、 Reed、Write、Connect、BindなどのI/Oオペレーションを提供しています。
NettyではChannelインターフェースを用意しており、以下のような実装が存在します。
- NioSocketChannel
- NIO selectorベースの実装
- OioSocketChannel
- 古いブロッキングI/Oを利用した実装
EventLoop、EventLoopGroupe
EventLoopGoupeは1つ以上のEventLoopを管理し、新しく作られたChannelにアロケートする役割を持っています。1つのChannelは1つのEventLoopが割り当てられ、そのライフサイクルの中で登録されたChannelのI/Oオペレーションをハンドルします。通常、1つのEventLoopに複数のChannelが登録されますが、実装によってはEventLoopとChannelが一体一になるものもあります。
EventLoopの実装には以下のようなものがあります。
- NioEventLoop
- ChannelをSelectorに登録して、それらの多重化を行います
- ThreadPerChannelEventLoop
- ChannelごとにEventLoopが割り当てられる同期OIOチャンネルをハンドリングします
ChannelHandler、ChannelPipeline
ChannelHandlerはChannelの状態の変化、データの取得などのネットワークイベントによって、フックされるメソッドを持ったコンポーネントです。Nettyでは、アプリケーションのロジックはこのHandlerに記述されます。 ソケットを外としたときの、データフローの方向によってInboundとOutboundそれぞれのハンドラーを作成することが可能で、 ChannelHandlerはChannelPipelineに登録され、Piplineの中で各方向のHandlerがチェインされていきます。このときHandlerはPiplelineに登録された順番でチェインされます。
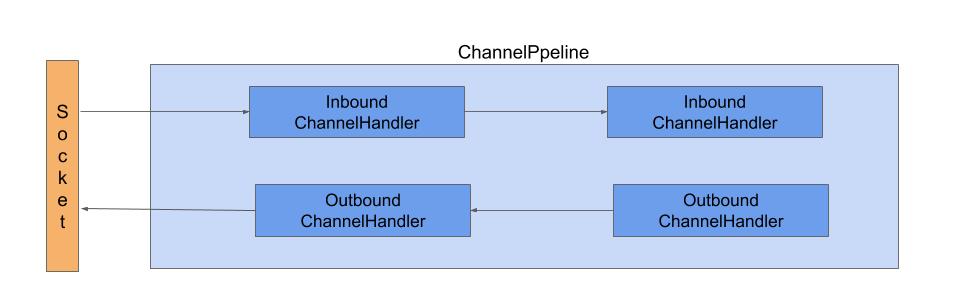
通常、Nettyをクライアントとして利用した場合はOutboundのデータフローを通り、サーバとして利用した場合はInboundのデータフローを通ることになります。
同じ、Pipeline内でInboundとOutbound両方のHandlerが登録されていた場合でも基本的にはそれぞれが交わってチェインされることがありません。ただし、InboundHanderでも、ChannelHandlerContext(後述)からChannelを取り出して直接ソケットへの書き込みを行った際にはOutboundのハンドラーがチェインされます。また、ChannelPilpelineへのハンドラーは動的に削除や追加を行なうことも可能です。
ChannelHandlerとChannelPipelineの説明をする上で、もう一つ欠かせないのが、ChannelHandlerContextです。ChannelHandlerContextは同じ方向のデータフローのHanlder群とChannelPipelineとのひも付きや、Channelそのものを持つコンテクストです。また、アプリケーションはこのコンテクストを通してHandlerはデータの送信を行ったり、他のハンドラーを呼び出したりすることが可能となります。Nettyでは2種類のデータ送信方法があり、前述したように直接Channelに書き込む方法と、このCannelHandlerContextを通して送信する方法があります。前者の場合はOutboundのHandlerがフックされ後者の場合はされません。
次の図はHandler群とChannelPipeline、そして、その関係性を示しています。

図に書いてあるとおり、HandlerはChannelHandlerContextを通して、次のハンドラーへのチェインを行います。
終わりに
細かいところで言うと、Nettyをクライアントとして利用する場合とサーバとして利用する場合でEventLoopの数が違ったりはするですが、ざっとまとめた、Nettyの全体像はこんな感じになっていると理解しています。
参考資料
NettyのChannelInboundHandlerとChannelOutboundHandleについてまとめる
はじめに
Netty In Actionを読んでいて、それぞれがのハンドラーがどのどのタイミングで実行されるかが分かりづらかったので、自身の頭の中の整理を目的に自分の理解をまとめて見ようと思います。
Inbound? OutBound?
ChannelPipelineでは、ソケットとアプリケーションを両端として、それぞれの方向に流れるデータフローをInboundとOutBoundと呼んでいます。
- ソケット⇨アプリケーション : Inbound
- アプリケーション⇨ソケット: Outbound
また、それぞれのデータフローのイベントに対して、ChannelPipelineには別の種類のハンドラーを登録することが可能で、そのハンドラーを実装するためのインターフェースが、ChannelInboundHandlerとChannelOutboundHandlerです。その名の通りそれぞれがソケットに空のInboundとOutboundのイベントで発火されます。
それぞれの方向で基本的に、Hndler間での関係性は無く、ChannelHandlertContextを通してお互いに相互作用はしません。
ChannelInboundHandler
ChannelInboundHandlerのデータに対するイベントで発火されるメソッドが定義されたInterfaceです。具体的には以下のようなものが定義されています。
| メソッド名 | 説明 |
|---|---|
| channelRegistered | EventLoopとChannelHandlertContextがChannelに登録され、何かのI/Oのハンドルが可能となった際に実行される |
| channelUnregistered | EventLoopとChannelHandlertContextがChannelから解除され、なにかのI/Oのハンドルが不可能となった際に実行される |
| channelActive | ChannelのChannelHndlerContextがアクティブ、チャンネルが接続もしくは、バインドされ準備ができた状態になった際に実行される |
| channelInactive | ChannelがActive状態ではなくなった際際に実行される。リモートの通信先と接続がキレている |
| channelReadComplete | readオペレーションが終わった際に実行される |
| channelRead | データがChannelから読み出された際に実行される |
| channelWritabilityChanged | ChannelのWritabilityの状態が変わった際に呼び出される。ユーザは書き込みがが終わっていないことを確認できたり、書き込み可能になった際に書き込みを行なうようにすることができる。その確認を行なうために、Channelのメソッドである、isWritable()メソッドを利用することができる。 |
| userEventTriggered | ChannelnboundHandler.fireUserEventTriggered()が呼ばれた際に実行される。 |
| exceptionCaught | 例外が投げられた際に実行される。 |
例えば以下のようなハンドラーをChannelPipelineに登録します。
@ChannelHandler.Sharable public class EchoInboundHandler extends ChannelInboundHandlerAdapter { @Override public void channelRegistered(ChannelHandlerContext ctx) throws Exception { System.out.println("channelRegistered inbound handler called"); super.channelRegistered(ctx); } @Override public void channelUnregistered(ChannelHandlerContext ctx) throws Exception { System.out.println("channelUnregistered inbound handler called"); super.channelUnregistered(ctx); } @Override public void channelActive(ChannelHandlerContext ctx) throws Exception { System.out.println("channelActive inbound handler called"); } @Override public void channelInactive(ChannelHandlerContext ctx) throws Exception { System.out.println("channelInactive inbound handler called"); super.channelInactive(ctx); } @Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { System.out.println("channelRead inbound handler called"); //送信されたデータをコンソールに出力してそのまま返す。 ByteBuf input = (ByteBuf) msg; System.out.println(input.toString(CharsetUtil.UTF_8)); ctx.write(input); } @Override public void channelReadComplete(ChannelHandlerContext ctx) throws Exception { System.out.println("channelReadComplete inbound handler called"); //読み込みが終了の際にコネクションをクローズする ctx.writeAndFlush(Unpooled.EMPTY_BUFFER) .addListener(ChannelFutureListener.CLOSE); } @Override public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception { super.userEventTriggered(ctx, evt); } @Override public void channelWritabilityChanged(ChannelHandlerContext ctx) throws Exception { super.channelWritabilityChanged(ctx); } }
TCPソケットの通信でaaaというデータを送った際には以下のような出力が標準出力にされます。channelActiveまでが、コネクションを確立されるまでに出力され、
channelRegistered inbound handler called channelActive inbound handler called channelRead inbound handler called aaa channelReadComplete inbound handler called channelInactive inbound handler called channelUnregistered inbound handler called
userEventTriggeredやchannelWritabilityChangedなどは、前述の表のようなタイミングで実行されるため、今回のケースでは実行されないようです。
ChannelOutboundHandler
Inboundに対して、ChannelOutboundHandlerに関しては、以下のようなメソッドが定義されています。
| メソッド名 | 説明 |
|---|---|
| bind(ChannelHandlerContext, SocketAddress,ChannelPromise) | ローカルアドレスにバインドがリクエストされた際に実行される |
| connect(ChannelHandlerContext, SocketAddress,SocketAddress,ChannelPromise) | リモートの通信先にChannelと接続のリクエストの際に実行される |
| disconnect(ChannelHandlerContext, ChannelPromise) | Channelのリモートの通信先とのコネクションを切断するリクエストを送る際に実行されます |
| close(ChannelHandlerContext,ChannelPromise) | Channelのクローズのリクエストの際に |
| disconnect(ChannelHandlerContext, ChannelPromise) | EventLoopからChannelの登録解除がリクエストされた際に実行されます。 |
| read(ChannelHandlerContext) | Channelのリードがリクエストされた際に実行されます |
| flush(ChannelHandlerContext) | Channelのキューに溜まったデータをフラッシュのリクエストの際に実行されます |
| write(ChannelHandlerContext,Object, ChannelPromise | Channelを通して書き込みがリクエストされる際に実行されます |
例えば以下の2つのようなハンドラーをChannelPipelineに登録します。
@ChannelHandler.Sharable public class EchoOutBoundHandler extends ChannelOutboundHandlerAdapter { @Override public void bind(ChannelHandlerContext ctx, SocketAddress localAddress, ChannelPromise promise) throws Exception { System.out.println("bind outbound handler called"); super.bind(ctx, localAddress, promise); } @Override public void connect(ChannelHandlerContext ctx, SocketAddress remoteAddress, SocketAddress localAddress, ChannelPromise promise) throws Exception { System.out.println("connect outbound handler called"); super.connect(ctx, remoteAddress, localAddress, promise); } @Override public void disconnect(ChannelHandlerContext ctx, ChannelPromise promise) throws Exception { System.out.println("disconnect outbound handler called"); super.disconnect(ctx, promise); } @Override public void close(ChannelHandlerContext ctx, ChannelPromise promise) throws Exception { System.out.println("close outbound handler called"); super.close(ctx, promise); } @Override public void deregister(ChannelHandlerContext ctx, ChannelPromise promise) throws Exception { System.out.println("deregister outbound handler called"); super.deregister(ctx, promise); } @Override public void read(ChannelHandlerContext ctx) throws Exception { System.out.println("read outbound handler called"); super.read(ctx); } @Override public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception { System.out.println("write outbound handler called"); super.write(ctx, msg, promise); } @Override public void flush(ChannelHandlerContext ctx) throws Exception { System.out.println("flush outbound handler called"); super.flush(ctx); } }
public class EchoClient extends SimpleChannelInboundHandler<ByteBuf> { @Override public void channelActive(ChannelHandlerContext ctx) throws Exception { // 通信先にhelloのメッセージを送信 ctx.writeAndFlush(Unpooled.copiedBuffer("hello", CharsetUtil.UTF_8)); super.channelActive(ctx); } @Override protected void channelRead0(ChannelHandlerContext ctx, ByteBuf msg) throws Exception { // 通信先からのレスポンスを表示 System.out.println(msg.toString(CharsetUtil.UTF_8)); } }
その状態でNettyをクライアントとして実行し、通信を行なうとコンソールに以下のような出力が行われます。
connect outbound handler called write outbound handler called flush outbound handler called read outbound handler called hello read outbound handler called read outbound handler called
Nettyでエコーサーバーを書く
はじめに
最近、Netty in Actionを読んでいるのですが、生のNettyを今まで触ったことがなかったのでHello, Worldとして、Echoサーバを書いてみたいと思います。あまり、Netty全体の要素に対して深堀すると言うよりはひとまず動かすのを目指し、その中で必要なものを少し深堀する感じでやろうと思います。
書いてみる
環境
実行環境は以下のとおり
$ uname -srvmpio Linux 5.4.0-54-generic #60-Ubuntu SMP Fri Nov 6 10:37:59 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux $ lsb_release -a LSB Version: core-11.1.0ubuntu2-noarch:security-11.1.0ubuntu2-noarch Distributor ID: Ubuntu Description: Ubuntu 20.04.1 LTS Release: 20.04 Codename: focal $ java --version openjdk 11.0.8 2020-07-14 OpenJDK Runtime Environment 18.9 (build 11.0.8+10) OpenJDK 64-Bit Server VM 18.9 (build 11.0.8+10, mixed mode) $ mvn -v Apache Maven 3.6.3 Maven home: /usr/share/maven Java version: 11.0.8, vendor: N/A, runtime: /home/someone/.sdkman/candidates/java/11.0.8-open Default locale: ja_JP, platform encoding: UTF-8 OS name: "linux", version: "5.4.0-54-generic", arch: "amd64", family: "unix"
プロジェクトを準備する
適当にMavenプロジェクトを作成し(私はIntelliJを使ってプロジェクトを作成しました)、Pomを以下のように書きます。
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>netty-http-client-example</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>11</maven.compiler.source> <maven.compiler.target>11</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>io.netty</groupId> <artifactId>netty-all</artifactId> <version>4.0.51.Final</version> <scope>compile</scope> </dependency> </dependencies> </project>
準備としては以上です。
やること
Nettyでサーバを書く際には大きく以下の2つをする必要があります。
- ChannelHanlderの実装を書く
- HanlderをChannelPipelineに登録し、起動の処理を記述する
ChannelHanlderの実装を書く
ChannelHandlerはネットワークイベントをトリガーとして実行されるメソッドを持ったインターフェースです。Nettyでは、このインターフェースを実装し、メソッドに対してアプリケーションロジックを記述することになります。
なお、このHanlderは、HandlerのコンテナであるChannelPilelineに登録され(実際の登録は事項で行いが)、Handlerが複数登録されている場合は処理がチェインされます。チェインの順番はPipelineへの登録順となります。
Hanlderには大きく分けて、Inbound用とOutbound用のものがありますがここでは深く触れません。
簡単にHanlderの説明をおえたので実際に受け取ったデータをそのまま返すだけのハンドラーを記述してみたいと思います。
import io.netty.buffer.ByteBuf; import io.netty.buffer.Unpooled; import io.netty.channel.ChannelFutureListener; import io.netty.channel.ChannelHandler; import io.netty.channel.ChannelHandlerContext; import io.netty.channel.ChannelInboundHandlerAdapter; import io.netty.util.CharsetUtil; @ChannelHandler.Sharable public class EchoHandler extends ChannelInboundHandlerAdapter { @Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { ByteBuf input = (ByteBuf) msg; System.out.println(input.toString(CharsetUtil.UTF_8)); ctx.write(input); } @Override public void channelReadComplete(ChannelHandlerContext ctx) throws Exception { ctx.writeAndFlush(Unpooled.EMPTY_BUFFER) .addListener(ChannelFutureListener.CLOSE); } @Override public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception { cause.printStackTrace(); ctx.close(); } }
今回はChannelInboundHandlerのベースクラスであるChannelInboundHandlerAdapterを用いてハンドラーを記述しています。Nettyではこのようなインターフェースのデフォルト実装を行ってくれている〇〇Adapterと名の付くベースクラスが複数用意されているので、必要なメソッドだけをオーバーライドすればよいようになっています。これらのベースクラスは単に次のハンドラーにイベントをパスするような実装になっているようです。
各メソッドで、受け取っているChannelHandlerContextはChannelPipelineや、他のハンドラーと相互作用を行なうためのコンテクストクラスです。
実装しているメソッドの簡単な説明を以下にまとめます。
- channelRead(ChannelHandlerContext ctx, Object msg)
- メッセージの入力があるたびに呼び出されます。上記の実装では受け取ったメッセージを標準出力に出力し、そのままChannelに同じ値を書き込んでいます。
- channelReadComplete(ChannelHandlerContext ctx)
- 読み込みオペレーションの最後に呼び出されます。
writeAndFlush()では、書き込んだデータをすべてクライアント側に送信しています。その後、ChannelFutureListener.CLOSEでChannelをクローズしています。
- 読み込みオペレーションの最後に呼び出されます。
- exceptionCaught(ChannelHandlerContext ctx, Throwable cause)
- 読み込みオペレーション時に例外がスローされた際に呼び出されます。スタックトレースを行い、Channelをクローズしています。
ちなみに、ここでは深く調べませんが、ChannelはScoketと直接コミュニケーションをとる役割をもつコンポーネントです。Channelに対して、1つのChannelPipelineが割り当てられて、ハンドラーの処理がチェインされていくイメージです。
HanlderをChannelPipelineに登録し、起動の処理を記述する
ここまでで、Handlerがかけたので、次にこのハンドラーをChannelPipelineに登録し、サーバを起動する処理を書きたいと思います。
import io.netty.bootstrap.ServerBootstrap; import io.netty.channel.ChannelFuture; import io.netty.channel.ChannelInitializer; import io.netty.channel.EventLoopGroup; import io.netty.channel.nio.NioEventLoopGroup; import io.netty.channel.socket.SocketChannel; import io.netty.channel.socket.nio.NioServerSocketChannel; import java.net.InetSocketAddress; public class Server { public static void main(String[] args) throws Exception { Server server = new Server(); server.run(); } public void run() throws Exception { final EchoHandler echoHandler = new EchoHandler(); EventLoopGroup group = new NioEventLoopGroup(); try { ServerBootstrap boot = new ServerBootstrap(); boot.group(group).channel(NioServerSocketChannel.class) .localAddress(new InetSocketAddress(8080)) .childHandler(new ChannelInitializer<SocketChannel>() { @Override protected void initChannel(SocketChannel socketChannel) throws Exception { socketChannel.pipeline() .addLast(echoHandler); } }); ChannelFuture cf = boot.bind().sync(); cf.channel().closeFuture().sync(); } finally { group.shutdownGracefully(); } } }
メインスレッドでは自分自身のrun()を呼び出しています。その中を上から見ていくと、まずはハンドラーをインスタンス化しています。これは後の登録のところで使います。
次にEventLoopGroupをインスタンス化しています。まず、EventLoopはコネクションのライフライムで発生するイベントをハンドリングする役割を持っています。EventLoop、1つに対して、1つのスレッドが割り当てられます。また、Channelは1つのEventLoopに割り当てられるのですが、その関係は多対一になり、1つのチャンネルは 1つのEventLoopに割り当てられ、1つのEventLoopは複数のチャンネルを割りてられる可能性があります。
EventLoopGroupの実装は、NioEventLoopGroupを利用しており、これは非同I/OのSelectorを使ったEventLoopGroupとなります。EventLoopGroupはEventLoopを管理するコンテナとなります、1つ以上のEventLoopを保持します。
try句の中では、まずServerBootstrapをインスタンス化しています。Nettyには2つのタイプのBootstrapの機構があり、ServerBooytstrapはNettyをクライアントではなくサーバーとして利用する際に利用する機構です。
インスタンス化したServerBootstrapに対して、上から順に以下のようなを設定していきます。
group()でEventLoopGroupeの登録channel()で、Channel作る際に利用するChannelクラスの登録。今回はNIOのSelecter用いた非同期IOを行なうNioServerSocketChannelを利用localAddress()でポートをバインドchildHandler()でハンドラーを登録。ChannelInitilizerはカスタムなChannelHandlerのセットをセットアップするためのHanlderで、チャンネルのHandlerを登録し終わったあとはChannelPipelineから削除されます。ここではEchoHandlerを登録しています。
ServerBootstrapの設定が終わったので、boot.bind()を呼び出して、サーバーをスタートさせます。
Telnetでつないでみる
telnetコマンドを使ってデータを送信します。アプリを起動します。私はinttelliJからメインメソッドを実行しましたが、以下のような感じでも起動できます。
$ mvn exec:java -Dexec.mainClass=server.Server
$ telnet localhost 8080 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. aaa aaa Connection closed by foreign host.
1つ目のaaaはこちらが送信したもので、2つめのaaaがサーバから返されるものです。
これで、Echoサーバができました。
Spring Boot 2.4.0についてメモ
はじめに
先週、(2020/11/12)にSpring Boot 2.4が出ましたが、どんなのが出たのかまとめて、なんとなく違いを把握おこうと思います。
基本的にはリリースブログとRelease Notesの内容を個人的に気になったところを少し深ぼって、自分の理解をまとめようと思うので、正確な情報は本家のブログやそれに付随する記事等をご参照ください(なるべく、情報ソースのリンクはつけます)。
ちなみに、ドキュメントに書かれた変更点を自分の理解でまとめたものなので、基本的に機能に対しては動作検証などは行っておりません。
Spring Boot 2.4.0変更点
このブログでは以下のような変更点についてまとめます。
- バージョニングスキーマの変更
- 設定ファイルのプロセッサ変更
- Volume Mounted Config Directory Trees
- Startupエンドポイントのサポート
- Docker/Buildpack Support
spring-boot-starter-testからJUnit 5’s Vintage Engineを削除- Java 15のサポート
この他、すべての変更点に関してはRelease Notesを参照してください。
バージョニングスキーマの変更
まず、今回のバージョンから新しいバージョンスキーマを利用するようです。
なので、今までは、2.3.4.RELEASEなどをPom等に記載していたと思いますが、今回のリリースからは2.4.0と記載するようになってます。
Spring Projectのバージョニング変更の詳細はこちらをご確認ください。
設定ファイルのプロセッサの変更
2.4よりapplication.popertiesやapplication.ymlの設定ファイルのプロセッシングロジックの見直しが行われているようです。新しいものはよりシンプルで、外部からの設定をより合理的な方法でロードするようになっています。
基本的には今までの設定ファイルを使えるようですが、例えば以下のような複雑な設定を行っている場合記述方法が変わっていたりするので注意が必要です。
spring.profiles<.*>のプロパティを利用しているMuti-document YAML Orderingを利用している
少しだけ注意点をまとめると、
プロファイルを利用している場合も注意が必要で、Jarの外部からapplication.popertiesを読み込む場合Jar内部のapplication-<profile>.popertiesを上書かないようになっているので気をつける必要があります。
また、Muti-document YAML Orderingを利用している場合(Yamlファイルを---セパレータで区切っている場合)その設定の反映順序が変わっています。2.3以前はプロファイルのアクティベーションの順序だったのが、Yaml内で宣言された順序で反映されるようになります。
詳細な、マイグレーションガイドについてはこちらをご覧ください。
ちなみに2.3以前のプロセッサで動かすことも可能で、その場合場spring.config.use-legacy-processing=trueを設定する必要があるようです。
Volume Mounted Config Directory Trees
spring.config.importプロバティが新しく追加され、Kubernetesなどの環境でVolumeマウントされたディレクトリ等からの設定をインポートすることが可能となりました。
spring.config.importを使った設定ファイルの読み込みは以下の2つのパターンで行なうことができます。
- すべての設定をコンテンツとして含む単一な(もしくは複数の)設定ファイルの読み込み
- ディレクトリーツリーに配置された、ファイル名が
keyでコンテンツがvalueとなるような設定の読み込み
前者については、例えば下記のように設定を行った場合、
spring.config.import=optional:file:./dev.properties
カレントディレクトリにdev.propertiesが存在すれば、その設定が既存の設定の上書きで反映されるようになります。このファイルは、複数指定することが可能で記述された順番で設定が読み込まれます。同じ設定を複数のファイルで行っている場合はあと勝ちになるようです。
ちなみにoptional:をつけることでファイルが存在しない場合になにもせずにスキップされるようになります。
後者についてはconfigtree:という表現を用いることでインポートが可能となります。
例えば、以下のようなディレクトリーツリーがあったとします。
etc/
config/
myapp/
username
password
ファイルのusernameとpasswordの中身が読み込みたい値です。
上記のディレクトリツリーに対して、以下のように設定を記述してやると値を読み込むことができます。
spring.config.import=optional:configtree:/etc/config/
この場合では、myapp.usernameとmyapp.passwordと言う設定をインジェクト(もしくはアサート)するようになります。
また、複数のディレクトリツリーを1つの親ディレクトリから読み込みたい場合などに置いてワイルドカードショートカットを利用して以下のように設定することができます。
spring.config.import=optional:configtree:/etc/config/*/
この場合、ディレクトリツリーが以下のようになっていると想定すると、
etc/
config/
dbconfig/
db/
username
password
mqconfig/
mq/
username
password
それぞれ、db.username、db.password、mq.username、mq.passwordのプロパティが追加されるようになります。
この機能は、主にKubernetes環境に置いての利用を想定されているようです。ComfigMap等の書き換えが行われたらその設定が反映されるようになると思われます。 (後からご指摘頂いたのですが、こちら間違えでした。書き換えが行われたとしても設定が動的に反映されなかったことを手元の環境で確認してます。)
ActuatorのStartupエンドポイントのサポート
Kubernetes 1.18以降では Start Up Probeという機能がベータから正式リリースされています。
これは、Liveness ProbeやReadiness Probeと並んで追加されたもので、コンテナ起動時にのみ使用されるProbeです。
自分の理解のために、少し本筋から外れて説明すると、起動の遅いアプリケーションナなどに対して、コンテナのデットロックに対する迅速な反応を損なわずにLiveness Probeを設定するのが難しい場合があります。起動が遅いアプリケーションに対応してLiveness Probeを長く設定してしまうと、その分コンテナの再起動が遅れてしまうからです。これに対して、Startup Probeはコンテナ起動時のみに利用されるLiveness Probeの機能を提供することによって既存の問題に対してより簡単な解決方法を提供しています。
このStartup Probeに対して、Spring Actuatorでは専用のエンドポイントが追加されています。
(こちらもあとから指摘いただいたのですが、Startup Probeとは関係が無かったよです。)
アプリケーションの起動時の情報を取得するためのエンドポイントが新たに追加されています。
このエンドポイントでは、予想よりも起動が遅いBeanの情報などのスタートアップに関する情報を取得することができます。
取得できる情報の詳細に関してはこちらをご覧ください。
Docker/Buildpack Support
イメージの公開
Mavenプラグインのspring-boot:build-imageゴールやbootBuildImageタスクを用いて、Dockerレジストリにイメージをこう買うすることが可能になったようです。
例えば、Mavenでは以下のような設定を追加してレジストリを登録しておきます。
<project> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <image> <name>docker.example.com/library/${project.artifactId}</name> <publish>true</publish> </image> <docker> <publishRegistry> <username>user</username> <password>secret</password> <url>https://docker.example.com/v1/</url> <email>user@example.com</email> </publishRegistry> </docker> </configuration> </plugin> </plugins> </build> </project>
ちなみにレジストリへの公開は以下のようなコマンドを用いても行なうことが可能です。
$ mvn spring-boot:build-image -Dspring-boot.build-image.imageName=docker.example.com/library/my-app:v1 -Dspring-boot.build-image.publish=true
認証
Spring BootのビルドパックサポートにおいてプライベートDockerレジストリに対する、username/password認証とトークン認証のどちらもサポートされるようになりました。
詳細に関してはこちらを参考にしてください。
spring-boot-starter-testからJUnit 5’s Vintage Engineを削除
spring-boot-starter-testからJUnit 5’s Vintage Engine(Junit4の記述で、Junit5のエンジンを利用する際に使われるエンジン)が削除されています。このため、アップグレードを行った際に、org.junit.Testがエラーで落ちるようになります。
もし、2.4以降でも、Vintage Engineを利用したい場合は以下のような依存を追加してやる必要があります。
<dependency> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.hamcrest</groupId> <artifactId>hamcrest-core</artifactId> </exclusion> </exclusions> </dependency>
Java 15のサポート
言葉通りです。
Java 8と11にも互換性があります。
依存のアップグレード
依存がアップグレードされています。詳細はこちらを確認ください。
参考資料
Docker BuildKitを使う
はじめに
Dockerの 18.09 以降にはBuildKitという機能が存在しますが、今までなんとなく使ってただけなのでちゃんとまとめてある程度理解しておきたいなと
Docker BuildKitとは
そもそもBuildKitそのものはDocker Engineとは別でMoby Projectで開発されていたものです。 キャッシュや処理の並列化、アーキテクチャの見直しによってソースコードをビルドアーティファクトへ変換する処理をより効率よく行なうことができるようになったり、Dockerfileの拡張文法を提供していたりします。Dockerの 18.09 以降はDocker Engineに拡張として取り込まれ、特に特別なインストールなどはなしに利用することができます。
何ができるん?
つまるところ、BuidKitはどういうことを可能にしてくれるのかということを以下にまとめます。
- ビルドの高速化される
- ビルドの標準出力に各ステップの実行時間が出力される
- Dockerfileの拡張文法が利用可能になる(後述)
使ってみる
環境
実行環境は以下の通り
$ docker version Client: Docker Engine - Community Version: 19.03.12 API version: 1.40 Go version: go1.13.10 Git commit: 48a66213fe Built: Mon Jun 22 15:45:36 2020 OS/Arch: linux/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 19.03.12 API version: 1.40 (minimum version 1.12) Go version: go1.13.10 Git commit: 48a66213fe Built: Mon Jun 22 15:44:07 2020 OS/Arch: linux/amd64 Experimental: false containerd: Version: 1.2.13 GitCommit: 7ad184331fa3e55e52b890ea95e65ba581ae3429 runc: Version: 1.0.0-rc10 GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd docker-init: Version: 0.18.0 GitCommit: fec3683 $ lsb_release -a LSB Version: core-11.1.0ubuntu2-noarch:security-11.1.0ubuntu2-noarch Distributor ID: Ubuntu Description: Ubuntu 20.04.1 LTS Release: 20.04 Codename: focal $ uname -srvmpio Linux 5.4.0-53-generic #59-Ubuntu SMP Wed Oct 21 09:38:44 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
Dockerfileを用意しておく
Docker BuildKitの機能を試すためにいかのDockerfileをベースにします。
特に明示してなければ以下のDcokerfileを利用してビルドを行っています。
FROM centos:7 RUN yum install -y java
BuildKit有効化
環境変数での有効化
BuildKitは環境変数にDOCKER_BUILDKIT=1と設定しておくと有効化されます。例えば単発のビルド時に有効化したい場合は以下のようにします。
$DOCKER_BUILDKIT=1 docker build .
デフォルトでの有効化
デフォルトで有効化するためには/etc/docker/daemon.jsonのfeatureの項目をtrueに設定します。
{ "features": { "buildkit": true } }
今回はデフォルトとの対比を行いたいのでこちらは使わず環境変数の方で指定して、BuildKitを使いたいと思います。
出力結果のが変わる
まずは普通にdocker buildした場合は以下のような出力になります。
$ docker build -t java-centos . Sending build context to Docker daemon 2.048kB Step 1/2 : FROM centos:7 ---> 7e6257c9f8d8 Step 2/2 : RUN yum install -y java ---> Using cache ---> 68dff4f570e9 Successfully built 68dff4f570e9 Successfully tagged java-centos:latest
次にBuildKitを有効化してDockerBuildを実行します。
$ DOCKER_BUILDKIT=1 docker build -t java-centos . [+] Building 0.0s (6/6) FINISHED => [internal] load .dockerignore 0.0s => => transferring context: 2B 0.0s => [internal] load build definition from Dockerfile 0.0s => => transferring dockerfile: 37B 0.0s => [internal] load metadata for docker.io/library/centos:7 0.0s => [1/2] FROM docker.io/library/centos:7 0.0s => CACHED [2/2] RUN yum install -y java 0.0s => exporting to image 0.0s => => exporting layers 0.0s => => writing image sha256:fc5361ee029af85ff2d83403afe003214d2dfcb539216b3fcfa1349852ed614a 0.0s => => naming to docker.io/library/java-centos
出力する項目がすこし変わっているのと、各工程にどのくらいの時間がかかったのかの計測結果が出力されるようになります。
また、--progress=plainを付け加えることで出力形式をプレーン?なものに変えることもできるみたいです。
$ DOCKER_BUILDKIT=1 docker build --progress=plain -t java-centos . #2 [internal] load build definition from Dockerfile #2 transferring dockerfile: 37B done #2 DONE 0.0s #1 [internal] load .dockerignore #1 transferring context: 2B done #1 DONE 0.0s #3 [internal] load metadata for docker.io/library/centos:7 #3 DONE 0.0s #4 [1/2] FROM docker.io/library/centos:7 #4 DONE 0.0s #5 [2/2] RUN yum install -y java #5 CACHED #6 exporting to image #6 exporting layers done #6 writing image sha256:fc5361ee029af85ff2d83403afe003214d2dfcb539216b3fcfa1349852ed614a done #6 naming to docker.io/library/java-centos done #6 DONE 0.0s
(いまのところこいつの利点があんまりわかってないが、余計な=>がなくなってるだけのかな...?)
BuildKitのフロンドエンドの置き換え
ここで言うフロントエンドとはBuildKitの中で動くビルドディフィニションをLLB(BuildKitが生成する中間バイナリフォーマット)に変換するコンポーネントのことを指します。Docker目線でいえばDockerfileをバイナリに変換するためのコンポーネントのことを指します。
Dcokerfileの先頭行に以下のような形式のコメントを追加することでこのフロントエンドを置き換えることができます。
# syntax = <frontend image>
現状Dockerfileのフロントエンドのイメージは以下の2つが用意されているようです。
後述しますが、フロントエンドを置き換えることによってDockerfile内でエクスペリメンタルな文法を利用することが可能となります。
フロントエンドを置き換えてエクスペリメンタルの機能を利用する(実験機能)
BuildKitを使ったDockerfileのビルドにおいて別フロントエンドを使うことで拡張の機能を利用することができます。
フロントエンドの置き換え
フロントエンドの置き換えに関しては前述していますが、今回使いたい機能を利用するために、Dockerfileの先頭にコメントを追加します。
# syntax=docker/dockerfile:experimental FROM centos:7 RUN yum install -y java
これで拡張文法とその機能を利用することが可能です。
拡張文法
置き換えたフロントエンドで便利そうな機能をいくつかまとめます。
RUN --mount=type=bind
--mount=type=bindはビルドコンテクスト(Dockerfileが置かれているワーキングディレクトリ)、もしくは、ビルドされるイメージコンテナのディレクトリをバインドすることができます。バインドされるディレクトリはデフォルトはリードオンリーです。
下記のような項目を,でつないで利用することができます。
| 項目 | 説明 |
|---|---|
| target(必須) | Dockerコンテナ内のマウント先のパス |
| from | ビルドストレージ、もしくはソースのルート。デフォルトはビルドのコンテクストにバインドされます |
| source | fromの中のソースパス、デフォルトのソースパスはfromのルートディレクトリ |
| rw,readwrite | マウントされたディレクトリに書き込むことを許可します。ただし、書き込んだデータは後に削除されます |
例えば下記のDockerfileではビルドコンテキストにあるDockerfileの内容をtext.txtに書き写しています。
# syntax=docker/dockerfile:experimental FROM busybox RUN --mount=type=bind,target=tmp cat tmp/Dockerfile > text.txt
下記のように実行するとビルドコンテキストがDokcerコンテナ内の/tmpにバインディングされ、Dockerfileの内容がtext.txtに書き移すことができます。
$ DOCKER_BUILDKIT=1 docker build -t busybox-tmp . [+] Building 2.1s (9/9) FINISHED => [internal] load build definition from Dockerfile 0.0s => => transferring dockerfile: 37B 0.0s => [internal] load .dockerignore 0.0s => => transferring context: 2B 0.0s => resolve image config for docker.io/docker/dockerfile:experimental 1.8s => CACHED docker-image://docker.io/docker/dockerfile:experimental@sha256:de85b2f3a3e8a2f7fe48e8e84a65f6fdd5cd5183afa6412fff9caa6871649c44 0.0s => [internal] load metadata for docker.io/library/busybox:latest 0.0s => [internal] load build context 0.0s => => transferring context: 31B 0.0s => [1/2] FROM docker.io/library/busybox 0.0s => CACHED [2/2] RUN --mount=type=bind,target=tmp cat tmp/Dockerfile > text.txt 0.0s => exporting to image 0.0s => => exporting layers 0.0s => => writing image sha256:d75bb6670538d7af739b6f201d170a5fa38128e7cbbcf56ef9448682695d0b36 0.0s => => naming to docker.io/library/busybox-tmp $ docker run busybox-tmp cat text.txt # syntax=docker/dockerfile:experimental FROM busybox RUN --mount=type=bind,target=tmp cat tmp/Dockerfile > text.txt
この機能のユースケースとしてはDockerコンテナ内に必要は無いけど実行はしたいスクリプトがあるディレクトリをバインドしたりすることが考えられます。
ちなみにですが、targetにコンテナ内に元来存在しないディレクトリを指定すると勝手にディレクトリを作成しそこに対してビルドコンテキスト(や指定されたビルドストレージ、もしくはイメージのディレクトリ)をバインドしてくれます。
RUN --mount=type=cache
コンパイラーやパッケージマネージャーのキャッシュディレクトリをバインドすることができます。
下記のような項目を,でつないで利用することができます。
| 項目 | 説明 |
|---|---|
| id | キャッシュを識別するためのID |
| target(必須) | Dockerコンテナ内のマウント先のパス |
| ro,readonly | セットされていればキャッシュがリードオンリーになります |
| from | キャッシュマウントを行なうビルドストレージ。デフォルトは空のディレクトリ |
| source | マウントを行なうfromの中のサブパス。デフォルトはfromのルート |
| mode | 新しいキャッシュディレクトリのファイルモード、デフォルトは0755 |
| uid | 新しいキャッシュディレクトリのUserID。デフォルトは0 |
| gid | 新しいキャッシュディレクトリのグループID。デフォルトは0 |
例えば下記のDockerfileはmavenのm2ディレクトリをキャッシュして、2回目以降は.m2のキャッシュが/root/.m2にマウントされるようになります。
# syntax = docker/dockerfile:1.1-experimental FROM maven:3.6.2-jdk-8-slim AS build-env ADD . /javasoerceroot WORKDIR /javasorceroot RUN --mount=type=cache,target=/root/.m2 mvn clean package
aptパッケージをキャッシュする場合以下のようにします。
# syntax = docker/dockerfile:experimental FROM ubuntu RUN rm -f /etc/apt/apt.conf.d/docker-clean; echo 'Binary::apt::APT::Keep-Downloaded-Packages "true";' > /etc/apt/apt.conf.d/keep-cache RUN --mount=type=cache,target=/var/cache/apt --mount=type=cache,target=/var/lib/apt \ apt update && apt-get --no-install-recommends install -y gcc
RUN --mount=type=tmpfs
tmpfsをコンテナへバインドすることができます。
下記のような項目を,でつないで利用することができます。
| 項目 | 説明 |
|---|---|
| target(必須) | Dockerコンテナ内のマウント先のパス |
RUN --mount=type=secret
秘密鍵のファイルようなクレデンシャルファイルに対して、をイメージの中に残すこと無くバインドすることができます。
| 項目 | 説明 |
|---|---|
| id | シークレットのID。ターゲットパスのデフォルトベース名として利用されます。 |
| target | Dockerコンテナ内のマウント先のパス。デフォルトでは/run/secrets/ + idとなります。 |
| required | trueでセットすると、シークレットが有効で無かった場合に命令がエラーとして取り扱われるようになります。デフォルトはfalseです |
| mode | シークレットのファイルモードデフォルトは0400 |
| uid | シークレットのユーザID。デフォルトは0 |
| gid | シークレットのグループID。デフォルトは0 |
例えばAWSのS3へアクセスしたいようなユースケースでは以下のようにします。
# syntax = docker/dockerfile:experimental FROM python:3 RUN pip install awscli RUN --mount=type=secret,id=aws,target=/root/.aws/credentials aws s3 cp s3://... ...
docker build時に--secretフラグを用いてバインドするクレデンシャルなファイルを渡します。
$ docker build --secret id=aws,src=$HOME/.aws/credentials .
その他機能はこちらをご覧ください。