pprofでGoアプリのプロファイル情報を取得する
はじめに
Javaでプロファイル情報を取得して分析するための方法は、いくつか思い当たるものはあるのですがGoだとやり方全くわからなかったので少しまとめておこうかと思いました。
Go言語は標準ライブラリとして、runtime/pprofパッケージやnet/http/pprofパッケージが用意されており、これらをちょっと使ってみようと思います。
また、プロファイル情報を分析するためのツールは公式のpprofを使うのが一般的なようなのでほんの少しだけ使い方をみてみようと思います。
pprofを用いたプロファイリング
Go言でプロファイル情報を取得するには以下の2つのやり方があるみたいです。
runtime/pprofパッケージを用いてプロファイル情報をファイルに出力するnet/http/pprofパッケージを用いてHTTP経由でプロファイル情報を取得する
上記の2つはprofile.proto形式で情報を出力するようです。
profile.protoは記号化されたコールスタックの情報がProtocol Buffersの書式で記述されているようです。
pprofで取得可能な項目には以下のようなものがあるようです。
- CPU: CPUの使用時間に関するプロファイル
- Heep: メモリアロケーションのプロファイル、メモリリークのチェック情報
- Threadcreate: OSのスレッド生成に関するプロファイル
- Goroutine: すべてのGoroutineのスタックトレース
- Block: Goroutineのブロッキングに関するプロファイル。デフォルトで無効なので
runtime.SetBlockProfileRateを使って有効化する必要がある。 - Mutex: Mutexのロックに関するプロファイル。デフォルトで無効なので
runtime.SetMutexProfileFractionを使って有効化する必要がある。
これらの詳細はこちらをご確認ください。
また軽く前述していますが、取得したprofile.protoの分析はpprofの可視化ツールを使って行なうのが一般的なようです。 このツールはのデータを読み込んで可視化を行ってくれます。
やってみる
フィボナッチ数列を計算する簡単なのアプリケーションを作成して、runtime/pprofパッケージやnet/http/pprofパッケージで情報を取得してみるのと、その情報を可視化するとことまでやってみようかと思います。
環境
動作環境は以下のような感じ。
$ uname -srvmpio Linux 5.4.0-84-generic #94-Ubuntu SMP Thu Aug 26 20:27:37 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux $ go version go version go1.17.1 linux/amd64 $ lsb_release -a LSB Version: core-11.1.0ubuntu2-noarch:security-11.1.0ubuntu2-noarch Distributor ID: Ubuntu Description: Ubuntu 20.04.3 LTS Release: 20.04 Codename: focal
サンプルアプリの作成
アプリは引数で正数nを受け取ってフィボナッチ数列を計算してn番目のフィボナッチ数を返すアプリを作ろうと思います。
まずはプロジェクト作成から。
$ mkdir echo-fibo && cd echo-fibo $ go mod init echo-fibo
次にfiboパッケージを作り、よくある定義のフィボナッチ数列を計算する関数を定義します。
また、その関数に対するテストも記述しておきます。
fibo.go
package fibo func Fibo(n int) int { if n < 2 { return n } return Fibo(n-2) + Fibo(n-1) }
fibo_test.go
package fibo import "testing" func TestFibo(t *testing.T) { tests := []struct { name string input int want int }{ { "input 10", 10, 55, }, { "input 11", 11, 89, }, { "input 20", 20, 6765, }, { "input 30", 30, 832040, }, { "input 44", 44, 701408733, }, } for _, tt := range tests { t.Run(tt.name, func(t *testing.T) { if got := Fibo(tt.input); got != tt.want { t.Errorf("Fibo() = %v, want %v", got, tt.want) } }) } }
ここでは、効率は度外視で直感的なフィボナッチ数列の計算アルゴリズムものを記述しました。
最後にこの関数を呼び出すmain関数を書きます。
package main import ( "echo-fibo/fibo" "fmt" "log" "os" "strconv" ) func main() { number, err := strconv.Atoi(os.Args[1]) if err != nil { log.Fatal(err) } fmt.Println(fibo.Fibo(number)) }
バリデージョンもなにもしてないほんとに最低限のものですが、pprofを動かすことが目的なだけなのでこのまま行きます。
runtime/pprofパッケージを用いてプロファイル情報を取得する
runtime/pprofパッケージを用いてプロファイル情報を取得する方法は以下の2通りの方法があります。
- Goのtestingパッケージにビルドインされているプロファイラを使う
pprof.StartCPUProfile(filename)やpprof.WriteHeapProfile(filename)等を使ってスタンドアローンアプリでプロファイルを有効化する
testingパッケージにビルドインされているプロファイラを使う
前者のやり方は簡単で、testingパッケージにはプロファイルのサポートがビルドインされているので、以下のコマンドを実行するだけでプロファイル情報を取得することが可能です。
$ cd fibo $ go test -cpuprofile cpu.prof -memprofile mem.prof -benchtime 1ms -bench . $ ls cpu.prof fibo.go fibo.test fibo_test.go mem.prof
上記のコマンドでは、-bench .ですべてのベンチマークが実行され、-cpuprofile cpu.profや-memprofile mem.profで実行結果を出力する項目とファイル名を決定しているようです。
上記の例ではCPUとMemoryに対するプロファイル情報を取得しましたが、以下のオプションでそれぞれのプロファイル情報が取得可能なようです。
| Option | 説明 |
|---|---|
| -blockprofile [outputFileName] | goroutineのブロッキングプロファイル |
| -coverprofile [outputFileName] | すべてのテストが実行された時のカバレッジプロファイル |
| -cpuprofile [outputFileName] | CPUプロファイル |
| -memprofile [outputFileName] | Memoryプロファイル |
| -mutexprofile | mutexの競合プロファイル |
また、プロファイルとは少し毛色が違いますが-trace [outputFileName]実行のトレースを出力することも可能なようです。
スタンドアローンアプリでプロファイルを有効化する
testingパッケージは利用せずスタンドアローンのアプリに対してプロファイルを実行したい場合は少し工夫が必要です。
pprof.StartCPUProfile(filename)やpprof.WriteHeapProfile(filename)などの関数をmain関数で呼び出しプロファイルを有効にできるようにする必要があるからです。 '
main.go`を以下のように書き換えます。
package main import ( "echo-fibo/fibo" "flag" "fmt" "log" "os" "runtime" "runtime/pprof" "strconv" ) var cpuprofile = flag.String("cpuprofile", "", "write cpu profile to `file`") var memprofile = flag.String("memprofile", "", "write memory profile to `file`") var number = flag.String("number", "", "fibo number") func main() { flag.Parse() if *cpuprofile != "" { f, err := os.Create(*cpuprofile) if err != nil { log.Fatal("could not create CPU profile: ", err) } defer f.Close() // error handling omitted for example if err := pprof.StartCPUProfile(f); err != nil { log.Fatal("could not start CPU profile: ", err) } defer pprof.StopCPUProfile() } fmt.Println(os.Args) num, err := strconv.Atoi(*number) if err != nil { log.Fatal(err) } fmt.Println(fibo.Fibo(num)) if *memprofile != "" { f, err := os.Create(*memprofile) if err != nil { log.Fatal("could not create memory profile: ", err) } defer f.Close() // error handling omitted for example runtime.GC() // get up-to-date statistics if err := pprof.WriteHeapProfile(f); err != nil { log.Fatal("could not write memory profile: ", err) } } }
この状態でアプリをビルドし以下のように起動するとプロファイル情報が取得できます。
$ go build echo-fibo $ ./echo-fibo -number 44 -memprofile mem.prof
1つ1つプロファイルごとに設定していくのは流石に面倒に感じますが、ラップしてくれているライブラリがあるみたいなのでこれを使えばもう少し楽にできるのかも知れません。また、別で試してみようと思います。
net/http/pprofパッケージ
net/http/pprofを用いればプロファイル情報をHTTP経由で公開することも可能です。
基本的な使い方は簡単で、以下のインポートを自分のプログラムに追加するだけです。
import _ "net/http/pprof"
ここで、注意が必要で、もしアプリケーションがhttp serverを起動していない場合に以下のようなコードを記述して自分で起動してやる必要があります。
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
net/http/pprofを使えばデフォルトでハンドラーが実装され以下のようなURLでプロファイル情報を取得できるようになります。
- http://localhost:6060/debug/pprof/goroutine
- http://localhost:6060/debug/pprof/heap
- http://localhost:6060/debug/pprof/threadcreate
- http://localhost:6060/debug/pprof/block
- http://localhost:6060/debug/pprof/mutex
- http://localhost:6060/debug/pprof/profile
- http://localhost:6060/debug/pprof/trace?seconds=5
また、すべてのプロファイル情報を取得する場合はhttp://localhost:6060/debug/pprof/で行けるみたいです。
main関数を以下のように書き換えてHTTPのパスパラメータで受け取った値のフィボナッチ数列の答えを返すアプリに変更します。
package main import ( "echo-fibo/fibo" "flag" "fmt" "log" "net/http" _ "net/http/pprof" "strconv" "strings" ) func main() { flag.Parse() http.HandleFunc("/fibo/", func(writer http.ResponseWriter, request *http.Request) { number := strings.TrimPrefix(request.URL.Path, "/fibo/") writer.WriteHeader(http.StatusOK) num, err := strconv.Atoi(number) if err != nil { log.Fatal(err) } fiboNum := fibo.Fibo(num) log.Println(fiboNum) fmt.Fprintf(writer, "The Answer is %d", fiboNum) }) log.Println(http.ListenAndServe("localhost:6060", nil)) }
普通のHTTPハンドラーの実装とサーバの起動を行っているだけですが、Importに_ "net/http/pprof"を追加しています。
wgetでプロファイル情報を取得してみます。
$ wget -O heep.prof http://localhost:6060/debug/pprof/heap --2021-09-23 18:47:58-- http://localhost:6060/debug/pprof/heap localhost (localhost) をDNSに問いあわせています... 127.0.0.1 localhost (localhost)|127.0.0.1|:6060 に接続しています... 接続しました。 HTTP による接続要求を送信しました、応答を待っています... 200 OK 長さ: 特定できません [application/octet-stream] `heep.prof' に保存中 heep.prof [ <=> ] 2.79K --.-KB/s in 0s 2021-09-23 18:47:58 (8.25 MB/s) - `heep.prof' へ保存終了 [2858] $ ls echo-fibo fibo go.mod go.sum heep.prof main.go
pprof 可視化ツールを使ってみる
pprofの可視化ではいくつかのやり方があるようです。
今回はWeb UIを通した可視化を行ってみたいと思います。
Web UIを用いる場合はgraphvizがインストールされている必要があるみたいなので、以下のコマンドでインストールしておきます。
sudo apt install graphviz
可視化ツールの使い方自体はさほど難しくなく以下のコマンドでWebのUIが立ち上がります。
$ go tool pprof -http=localhost:8081 pprof heep.prof pprof: open pprof: no such file or directory Fetched 1 source profiles out of 2 Serving web UI on http://localhost:8081
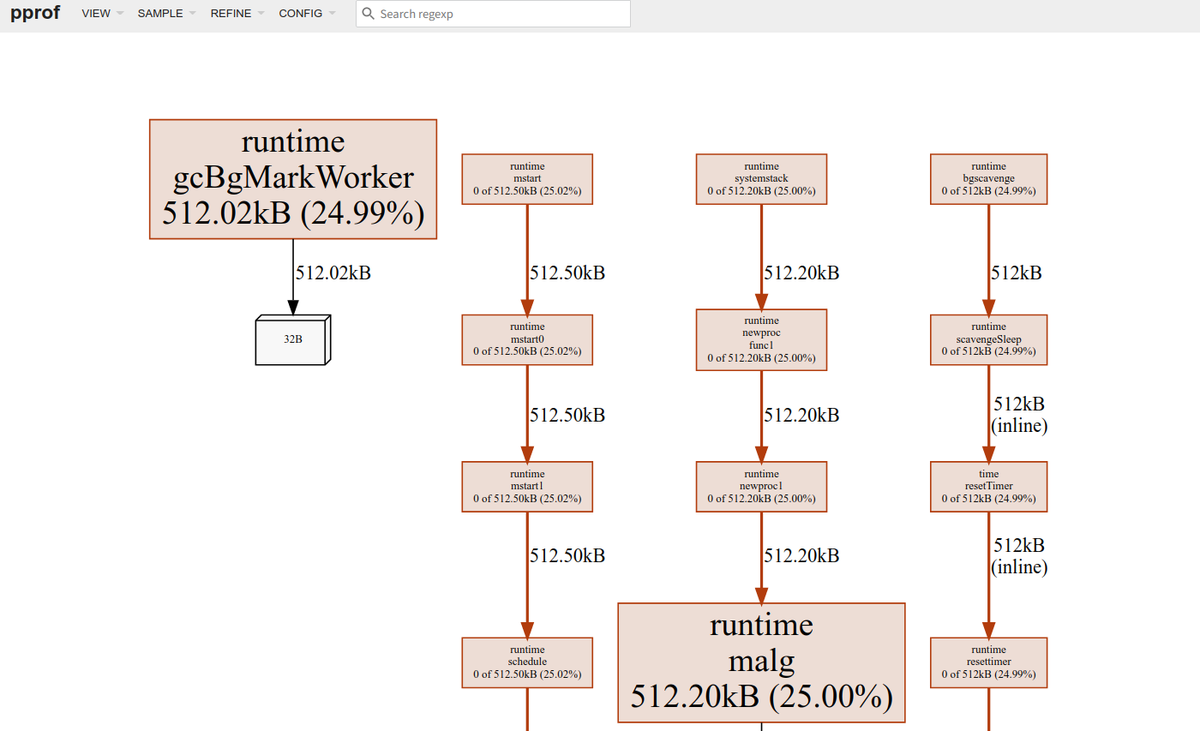
HTTP経由でプロファイルを取得する場合は以下のようにします。
$ go tool pprof -http=localhost:8082 http://localhost:6060/debug/pprof/heap Fetching profile over HTTP from http://localhost:6060/debug/pprof/heap Saved profile in /home/someone/pprof/pprof.___go_build_echo_fibo.alloc_objects.alloc_space.inuse_objects.inuse_space.005.pb.gz Serving web UI on http://localhost:8082
力尽きたのでUIの詳細な見かたは別の機会に。
Docker Notaryで署名したイメージをDockerHubで公開する
はじめに
ソフトウェアをインストールするさいにHashの検証や署名の検証などで、ダウンロードしてきたバイナリの信頼性を検証するみたいなのはよくやると思います。Dockerのイメージに対してこれがどのように解決されるかというところに理解が浅かったので、Dockerのコンテントトラストのドキュメントを読みつつ、自分で作成したイメージに署名をするところまでやってみようかと思います。
どのようにDocker のコンテントトラストが実現されるか
DockerではDCT(Docker Content Trust)と呼ばれる機能でデジタル署名を利用してデータの整合性と公開者情報を検証できる仕組みを提供しているようです。
この機能を使うと特定のイメージタグに対して検証を行えるようになります。
DCTでは、タグ毎にサインを行いどのタグにサインを行なうかはイメージの公開者が決める必要があります。
また、1つのリポジトリで1つのイメージに対してサインされているタグは1つだけ存在するようです。
クライアント目線で言うと、DCTを有効にした場合実行できるイメージはサインされたイメージのみで、ほかは利用できなくなります。フィルターの概念が近いようです。
Notaryについて
Docker DCTの仕組みはNotrayという機能の上で実装されているみたいです。
Notrayはサーバサイドとクライアントサイドで提供されており、サーバサイドが利用するDockerリポジトリにアタッチされている必要があるようです。
このブログでは独自にリポジトリを用意してアタッチすることなどは行いません(そのやり方に付いてはこちらを確認ください)。
今回はDocker Hubを使います。
また、NotrayはTOFU(Trust On First Use)というモデルを採用しており、最初にダウンロードしたものを信じるという仕様になってます。
V2ではこれを改善するような議論がコミュニティで行われているようです(ソースを見つけられなかった...)
自分で作成したイメージに署名する
環境
今回は以下の環境で諸々を動かしてみます。
$ lsb_release -a LSB Version: core-11.1.0ubuntu2-noarch:security-11.1.0ubuntu2-noarch Distributor ID: Ubuntu Description: Ubuntu 20.04.2 LTS Release: 20.04 Codename: focal $ uname -srvmpio Linux 5.4.0-80-generic #90-Ubuntu SMP Fri Jul 9 22:49:44 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux $ docker version Client: Docker Engine - Community Version: 20.10.8 API version: 1.41 Go version: go1.16.6 Git commit: 3967b7d Built: Fri Jul 30 19:54:27 2021 OS/Arch: linux/amd64 Context: default Experimental: true Server: Docker Engine - Community Engine: Version: 20.10.8 API version: 1.41 (minimum version 1.12) Go version: go1.16.6 Git commit: 75249d8 Built: Fri Jul 30 19:52:33 2021 OS/Arch: linux/amd64 Experimental: true containerd: Version: 1.4.9 GitCommit: e25210fe30a0a703442421b0f60afac609f950a3 runc: Version: 1.0.1 GitCommit: v1.0.1-0-g4144b63 docker-init: Version: 0.19.0 GitCommit: de40ad0
イメージの作成
まずは署名を行なうイメージを作っておきます。
今回はnginxの公式イメージを使って作ります。
$ docker create nginx $ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 896fa7872413 nginx "/docker-entrypoint.…" 27 seconds ago Created cranky_dewdney $ docker commit 896fa7872413 hirohiroyuya/nginx:singed sha256:ffcb0c4915f34a5d68f4eb6e8452db191d4c19e6ecfc4bc17a90b16689e0dfaa $ docker commit 896fa7872413 hirohiroyuya/nginx:non-singed sha256:8e321e701fd6f0f5bf730dfd55c464804f85570e0dcb31326f6e50e4c289b8a4 $ docker images REPOSITORY TAG IMAGE ID CREATED SIZE hirohiroyuya/nginx non-singed 8e321e701fd6 About a minute ago 133MB hirohiroyuya/nginx singed ffcb0c4915f3 About a minute ago 133MB nginx latest 08b152afcfae 3 weeks ago 133MB
今回は2つのタグを作り片方は署名しもう片方は署名せずにPushしようと思います。 下準備は完了です。
鍵の作成とNotaryサーバへの設定
署名をする前に鍵を作る必要があります。
鍵を作る場合には以下のコマンドを実行します。
$ docker trust key generate henoheno Generating key for henoheno... Enter passphrase for new henoheno key with ID 3eb42d4: Repeat passphrase for new henoheno key with ID 3eb42d4: Successfully generated and loaded private key. Corresponding public key available: /home/someone/henoheno.pub
今回は試しませんがすでに鍵がある場合は以下のようにして既存のロードできるみたいです。
$ docker trust key load key.pem --name jeff
次に作成された公開鍵を公開鍵を Notary サーバーへ追加します。 今回はDockerHubを使うので特にドメインなどは指定してませんが、必要な場合は指定してください。
$ docker trust signer add --key /home/yuya-hirooka/henoheno.pub henoheno hirohiroyuya/nginx Adding signer "henoheno" to hirohiroyuya/nginx... Enter passphrase for repository key with ID 7d993ef: Successfully added signer: henoheno to hirohiroyuya/nginx
ここまでで鍵の生成とサーバへの設定は終了です。
署名したイメージとしてないイメージをリポジトリにPushする
署名は以下のコマンドで行なうことができます。
$ docker trust sign hirohiroyuya/nginx:singed Signing and pushing trust data for local image hirohiroyuya/nginx:singed, may overwrite remote trust data The push refers to repository [docker.io/hirohiroyuya/nginx] e3135447ca3e: Mounted from library/nginx b85734705991: Mounted from library/nginx 988d9a3509bb: Mounted from library/nginx 59b01b87c9e7: Mounted from library/nginx 7c0b223167b9: Mounted from library/nginx 814bff734324: Mounted from library/nginx singed: digest: sha256:505db062138c1e3dd094c9e5811c6cd9baae8c7beb77b1c010db809f2e0d8fd3 size: 1570 Signing and pushing trust metadata Enter passphrase for henoheno key with ID 3eb42d4: Successfully signed docker.io/hirohiroyuya/nginx:singed
イメージをPushします。
この際にDOCKER_CONTENT_TRUST=1を環境変数に指定してコンテントトラストを有効にする必要があるようです。
$ DOCKER_CONTENT_TRUST=1 docker push hirohiroyuya/nginx:singed The push refers to repository [docker.io/hirohiroyuya/nginx] e3135447ca3e: Layer already exists b85734705991: Layer already exists 988d9a3509bb: Layer already exists 59b01b87c9e7: Layer already exists 7c0b223167b9: Layer already exists 814bff734324: Layer already exists singed: digest: sha256:505db062138c1e3dd094c9e5811c6cd9baae8c7beb77b1c010db809f2e0d8fd3 size: 1570 Signing and pushing trust metadata Enter passphrase for henoheno key with ID 3eb42d4: Successfully signed docker.io/hirohiroyuya/nginx:singed
これでDockerHubでの公開が完了しました。

Pushしたイメージの署名の情報を見るためには以下のコマンドを実行します。
$ docker trust inspect --pretty hirohiroyuya/nginx:singed Signatures for hirohiroyuya/nginx:singed SIGNED TAG DIGEST SIGNERS singed 12d3e6084e8af99509bd65b1d4583953cfb0791ddd66c4db199b725f6463327c henoheno List of signers and their keys for hirohiroyuya/nginx:singed SIGNER KEYS henoheno 3eb42d4ad775 Administrative keys for hirohiroyuya/nginx:singed Repository Key: 7d993ef2d41d5473aa8556e987cf8449bda7edd07b34856a13788a495bf70e3c Root Key: 9f0717638ac4ef0e113004354e2946c8010e2f6cb5b425af4d0779986ad45c74
Pushしたイメージを利用する
まずは、比較を行なうために先程のhirohiroyuya/nginx:non-singedの方もPushしておきます。
また、ローカルのイメージも綺麗にしておきます。
$ docker push hirohiroyuya/nginx:non-singed The push refers to repository [docker.io/hirohiroyuya/nginx] e3135447ca3e: Layer already exists b85734705991: Layer already exists 988d9a3509bb: Layer already exists 59b01b87c9e7: Layer already exists 7c0b223167b9: Layer already exists 814bff734324: Layer already exists non-singed: digest: sha256:1ab4fc461a4c9028fa375aefec46c862d9317a2b2009321273c0135f7bdcb6ec size: 1570 $ docker rmi -f $(docker images -a -q) $ docker images REPOSITORY TAG IMAGE ID CREATED SIZE

これでOK。
DockerクライアントではDCTはデフォルトで無効になっているようです。
これを有効にするためにはDOCKER_CONTENT_TRUST=1を環境変数に指定してコマンドを実行する必要があるようです。
署名が行われていない状態のnginx:non-signedをdocker runしてみます。
$ DOCKER_CONTENT_TRUST=1 docker run hirohiroyuya/nginx:non-singed docker: No valid trust data for non-singed.
実行できないようになってますね。
今度は、署名がされているものをdocker runしてみます。
$ DOCKER_CONTENT_TRUST=1 docker run hirohiroyuya/nginx:singed /docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration /docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/ /docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh 10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf 10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf /docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh /docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh /docker-entrypoint.sh: Configuration complete; ready for start up 2021/08/14 07:41:54 [notice] 1#1: using the "epoll" event method 2021/08/14 07:41:54 [notice] 1#1: nginx/1.21.1 2021/08/14 07:41:54 [notice] 1#1: built by gcc 8.3.0 (Debian 8.3.0-6) 2021/08/14 07:41:54 [notice] 1#1: OS: Linux 5.4.0-80-generic 2021/08/14 07:41:54 [notice] 1#1: getrlimit(RLIMIT_NOFILE): 1048576:1048576 2021/08/14 07:41:54 [notice] 1#1: start worker processes 2021/08/14 07:41:54 [notice] 1#1: start worker process 36 2021/08/14 07:41:54 [notice] 1#1: start worker process 37 2021/08/14 07:41:54 [notice] 1#1: start worker process 38 2021/08/14 07:41:54 [notice] 1#1: start worker process 39 2021/08/14 07:41:54 [notice] 1#1: start worker process 40 2021/08/14 07:41:54 [notice] 1#1: start worker process 41 2021/08/14 07:41:54 [notice] 1#1: start worker process 42 2021/08/14 07:41:54 [notice] 1#1: start worker process 43
きちんと実行ができました。
この通り、クライアントサイドではDCTを有効にしている場合、署名されたものしか実行されず更に検証も行われているようです。
SkaffoldとHelmを使い環境の設定を切り替えてk8sリソースをデプロイする
はじめに
以前のブログでSkaffoldのローカルでの開発機能を試しました。もちろんSkaffoldはローカルでの開発をサポートするツールにとどまらず、テストやビルド、デプロイなどもサポートしています。
デプロイをおこない場合は環境ごとの変数をうまく切り替える必要があると思いますが、SkaffoldはHelmのサポートを行っているのでそいつを使えばうまくできそうだったので試してみようかと思います。
SkaffoldはProfilesという機能を持っておりコンテキストごとのデプロイ、テスト、ビルドを切り替えることができますが、今回はその機能は使わずにTemplated Fieldsの機能を使ってやってみたいと思います。
やってみる
Java/Springのアプリケーション作ってやってみようと思います。
ローカルのクラスターはMinikube(Docker Driver)を使って作成します。
環境
今回の実行環境は以下の通りです。
$ uname -srvmpio Linux 5.4.0-80-generic #90-Ubuntu SMP Fri Jul 9 22:49:44 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux $ lsb_release -a LSB Version: core-11.1.0ubuntu2-noarch:security-11.1.0ubuntu2-noarch Distributor ID: Ubuntu Description: Ubuntu 20.04.2 LTS Release: 20.04 Codename: focal $ minikube version minikube version: v1.22.0 commit: a03fbcf166e6f74ef224d4a63be4277d017bb62e $ kubectl version -o yaml clientVersion: buildDate: "2021-03-18T01:10:43Z" compiler: gc gitCommit: 6b1d87acf3c8253c123756b9e61dac642678305f gitTreeState: clean gitVersion: v1.20.5 goVersion: go1.15.8 major: "1" minor: "20" platform: linux/amd64 serverVersion: buildDate: "2021-06-16T12:53:14Z" compiler: gc gitCommit: 092fbfbf53427de67cac1e9fa54aaa09a28371d7 gitTreeState: clean gitVersion: v1.21.2 goVersion: go1.16.5 major: "1" minor: "21" platform: linux/amd64 $ skaffold version v1.29.0
Springアプリケーションの作成
今回はアプリケーションが環境ごとの変数の文字列を読み取ってリクエスト側に返すようなアプリケーションを作成します。
Spring Initializrで以下の設定でアプリを作成します。

ダウンロードしたZipを適当なIDEなどで開いて、SkaffoldDeployApplicationを編集し以下の用にコントローラーを作成しプロパティファイルから読み込んだ値を返す用に指定しておきます。
@SpringBootApplication @RestController @PropertySource("classpath:application.properties") public class SkaffoldDeployApplication { @Value("${skaffold.env}") private String env; @GetMapping("/envval") public String env() { return env; } public static void main(String[] args) { SpringApplication.run(SkaffoldDeployApplication.class, args); } }
読み込むプロパティをapplication.proertiesに記述します。
skaffold.env=test
デフォルトではdevの文字列が変えるようになりますが、Spring Bootではこの値を環境変数SKAFFOLD_ENVで上書きすることができます。(変数の上書き順序に関してはこちらを確認してください’)
アプリケーションを起動して、cURLを叩いてみます。
$ mvn spring-boot:run $ curl localhost:8080/envval test
デフォルトの文字列であるdevが返ってきますね。
SkaffoldとHelmを初期化する
プロジェクトルートで、以下のコマンドでSkaffoldの初期化を行います。
$ skaffold init -k helm
apiVersion: skaffold/v2beta20
kind: Config
metadata:
name: skaffold-deploy
deploy:
kubectl:
manifests:
- helm
? Do you want to write this configuration to skaffold.yaml? Yes
Configuration skaffold.yaml was written
You can now run [skaffold build] to build the artifacts
or [skaffold run] to build and deploy
or [skaffold dev] to enter development mode, with auto-redeploy
この際にSkkafoldはマニフェストの位置を指定してやる必要があるため-kオプションで指定します。
このディレクトリは存在する必要なないので、とりあえず作りたい場合は適当に埋めておきます。
次にHelmの初期化を行います。
プロジェクトのルートで、以下のコマンドを実行し初期化します。
$ helm create helm Creating helm
すると以下のようなファイルが作成されます。
$ tree helm helm ├── Chart.yaml ├── charts ├── templates │ ├── NOTES.txt │ ├── _helpers.tpl │ ├── deployment.yaml │ ├── hpa.yaml │ ├── ingress.yaml │ ├── service.yaml │ ├── serviceaccount.yaml │ └── tests │ └── test-connection.yaml └── values.yaml
不要なファイルもいくつかありますが、今はは一旦そのままにして先に進みます。
Helmのマニフェストを書き換える
helm createでできあがったテンプレートを書き換えたり不要なファイルを削除したりします。
今回はServiceとDeploymentテンプレートのみで構成する簡単な環境を構築しようと思います。
ingress.yaml、serviceaccount.yaml、test/test-connection.yaml、_helpers.tpl、NOTES.txtを削除します。
次に、deployment.yamlのテンプレートを以下のように書き換えます。
apiVersion: apps/v1 kind: Deployment metadata: name: spring-app labels: app: spring-app spec: replicas: {{ .Values.replicaCount }} selector: matchLabels: app: spring-app template: metadata: labels: app: spring-app spec: containers: - name: spring-app image: {{ .Values.image }} ports: - name: http containerPort: {{ .Values.app.port }} protocol: TCP env: - name: SKAFFOLD_ENV value: {{ .Values.app.env }} - name: SERVER_PORT value: {{ .Values.app.port }}
変数としてSKAFFOLD_ENVとPod数、イメージを変えられるように設定しています。
同じようにservice.yamlも書き換えます。
apiVersion: v1 kind: Service metadata: name: spring-app labels: app: spring-app spec: type: ClusterIP ports: - port: {{ .Values.service.port }} targetPort: {{ .Values.app.port }} protocol: TCP name: http selector: app: spring-app
ここではポートだけがDevelopmentの方の設定と同じ用になるように設定しています。
次にテンプレートに対するで、デベロップメントと用とプロダクション用の2種類のvalues.yamlを用意します。
まずは、デベロップメントようのvalues-dev.yamlです
replicaCount: 2 image: spring-app app: port: 8081 env: dev service: type: NodePort port: 8081
Podのレプリカ数を2に設定し、環境をdevで設定しています。
imageはSkaffoldでビルドするイメージを使うようにしておきます。
また、このブログではあまり重要ではありませんが、デベロップメント環境へのデプロイということでServiceのtypeもNodePortにしています。
次に、プロダクション用のvalues-prod.yamlを用意します。
replicaCount: 4 image: spring-app app: port: 8081 env: prod service: type: ClusterIP port: 8081
先程のデベロップメントとの違いでいえば、レプリカ数を4に変え、環境をprodで指定しています。
また、こちらも重要ではありませんが、プロダクション環境へのデプロイということでServiceのtypeはClusterIPにしています。
Skaffold側でHelmを使うように設定する
Helmの方の設定が終わったのでSkaffoldから利用する設定を記述します。
skaffold.yamlを以下のように書き換えます。
apiVersion: skaffold/v2beta20
kind: Config
metadata:
name: skaffold-deploy
build:
artifacts:
- image: spring-app
buildpacks:
builder: gcr.io/buildpacks/builder:v1
deploy:
helm:
releases:
- name: spring-app
namespace: default
artifactOverrides:
image: spring-app
chartPath: helm
valuesFiles:
- "{{ .VALUES_FILE }}"
portForward:
- resourceType: service
resourceName: spring-app
port: 8081
buildディレクティブではBuildpacksを使ってアプリのBuildを行っています。
ここでのイメージ名を先程のvalues-*.yamlで書いた値と合わせておきます。
今回はローカルでビルドしたイメージを使うためこのような構成にしていますが、本来的にはDockerりぽじとりを使うことになると思います。
次に、deployディレクティブですがHelmの設定を行っています。注目すべきはchartPathとvaluesFiles部分でそれぞれHelm ChartとValuesファイルの置き場所を指します。
valuesFilesには"{{ .VALUES_FILE }}"という記述をしており、これはSkaffoldのTemplated Fieldsという機能を利用しています。
これで環境変数VALUES_FILEで指定されるvalue-*.yamlが実際のデプロイ時に使われるようになります。
最後のportForwardはk8sのPort Fowordの設定です。書いてあるとおりですが、名前がspring-appであるServiceに対して8081:8081でPort Forwordを行います。
これでプロジェクトの作成と諸々の設定は完了です。
アプリをデプロイする
それでは、アプリをデプロイしていきます。
Skaffoldにはdeployコマンドや、buildとdeployを合わせたrunコマンドなどがありますが、今回は検証のためにPort Forwordを行いたいためdevコマンドを使います。
まずは、デベロップメントを想定したデプロイです。
以下のコマンドを実行します。
$ VALUES_FILE=./helm/values-dev.yaml skaffold dev
初回起動に時間がかかりますが、起動すれば、アプリケーションのログが流れ始めます。
これでvalues-dev.yamlがテンプレートに反映されたリソースがデプロイされているはずです。
cURLでリクエストを送ったり、Podの数を確認したりしてみましょう。
$ curl localhost:9000/envval dev $ kubectl get deployment/spring-app NAME READY UP-TO-DATE AVAILABLE AGE spring-app 2/2 2 2 45m
Podが2個起動され、cURLでdevの値が返ってきているので、想定通りですね。
次にプロダクションを想定したデプロイです。
$ VALUES_FILE=./helm/values-prod.yaml skaffold dev
アプリケーションログが流れ始めたら。 先ほどと同じように確認してみます。
$ curl localhost:8081/envval prod $ kubectl get deployment NAME READY UP-TO-DATE AVAILABLE AGE spring-app 4/4 4 4 114s
本番用の設定でデプロイされていますね。
jcmdで何ができるかをまとめる
はじめに
jcmdは起動しているJavaプロセスのGCの統計情報をとったり、JFR起動したり諸々のことを行なうのによく使われるツールかと思います。
今まで必要になったコマンドを調べて使うぐらいしかしたことなかったのですが、実際どのくらいのことができるのか、ツールの全体感を把握できてなかったのでまとめてみようかと思います。
また、その中でJVMについても薄く学べればよいかと思います。
基本的にはオラクルのドキュメントやツールのマニュアルを元に書いていますが、あくまで自分の理解をまとめているものと捉えていただけるとありがたいです。
そして、もし間違え等あればご指摘いただけると嬉しいです。
環境
今回、動作確認に用いるJDKやその動作環境は以下のとおりです。
$ java --version openjdk 16 2021-03-16 OpenJDK Runtime Environment (build 16+36-2231) OpenJDK 64-Bit Server VM (build 16+36-2231, mixed mode, sharing) $ uname -srvmpio Linux 5.4.0-80-generic #90-Ubuntu SMP Fri Jul 9 22:49:44 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux $ lsb_release -a LSB Version: core-11.1.0ubuntu2-noarch:security-11.1.0ubuntu2-noarch Distributor ID: Ubuntu Description: Ubuntu 20.04.2 LTS Release: 20.04 Codename: focal
jcmd
そもそもjcmdってなんなのか?
manコマンドで出力されるマニュアルにはシンプルに以下のように書かれます。
Sends diagnostic command requests to a running Java Virtual Machine (JVM).
JVMに対して診断用のコマンドを送るためのツールだそうです。このコマンドをつかうとJVMに関する様々な情報を取得できたり、JVMに対する指示を送ったりすることができます。具体的にに何ができるかはあとでみていきます。
基本的にjcmdはJVMが起動しているマシンと同一マシンかつJVMを起動したユーザと同じもしくはユーザグループに所属している必要があるみたいです。
ただ、DiagnosticCommandMBeanインターフェースを使えば外部プロセスからも診断コマンドを送ることが可能になるみたいですが、まずは基本的な使い方をまとめたいのでこのブログでは深くはおいません。
JDKにはjcmd以外にもjstackやjmapのようなコマンドも用意されていますが、基本的にはjcmd1つでなんでもできるみたいです。
基本的な使い方
jcmdコマンドは以下の構成を取ります。
jcmd pid|main-class PerfCounter.print jcmd pid|main-class -f filename jcmd pid|main-class command[ arguments]
使用方法は大きく3つのパターンがありますが、第一引数にJavaのpidもしくはメインクラスの名前が来る点は変わりません。
メインクラス指定を行なうと同じ名前のメインクラスを持つすべてのプロセスの情報を取得するようです。
また、pidに0を指定するとすべてのJavaプロセスに診断コマンドを送信します。
また、引数なし、もしくは-lオプション使って実行すると実行中のJavaプロセスの一覧を出力します。
$ jcmd -l 11234 com.intellij.idea.Main 11791 jdk.jcmd/sun.tools.jcmd.JCmd -l
上記はIntelliJのpidとjcmd自身のpidが出力されています。
PerfCounter.printは指定したプロセス(もしくはクラス)のパフォーマンスカウンターを出力します。
$ jcmd 11234 PerfCounter.print 11234: java.ci.totalTime=65102836647 java.cls.loadedClasses=55377 java.cls.sharedLoadedClasses=0 java.cls.sharedUnloadedClasses=0 java.cls.unloadedClasses=178 (省略)
jcmd pid|main-class command[ arguments]のパターンでは第二引数に診断コマンドを受け取ります。
詳細は後ほどまとめますが、GC.heap_infoをコマンドとして渡すと以下のようにGCの一般的な情報が出力されます。
$ jcmd 11234 GC.heap_info 11234: par new generation total 261120K, used 118880K [0x0000000080000000, 0x0000000091b50000, 0x00000000a9990000) eden space 232128K, 51% used [0x0000000080000000, 0x0000000087418068, 0x000000008e2b0000) from space 28992K, 0% used [0x000000008e2b0000, 0x000000008e2b0000, 0x000000008ff00000) to space 28992K, 0% used [0x000000008ff00000, 0x000000008ff00000, 0x0000000091b50000) concurrent mark-sweep generation total 579960K, used 293996K [0x00000000a9990000, 0x00000000ccfee000, 0x0000000100000000) Metaspace used 373150K, capacity 388822K, committed 394296K, reserved 1388544K class space used 48366K, capacity 54385K, committed 56128K, reserved 1048576K
jcmd pid|main-class -f filenameでファイル名を指定して渡すとふくすうのコマンドをJavaプロセスに送信することができます。
例えば以下のようなファイルを用意します。
$ cat command.txt # コメント GC.heap_info VM.flags
このファイルを以下のようにコマンドに渡してやると、ヒープの情報とフラグの情報を取得することができます。
$ jcmd 11234 -f command.txt 11234: Command executed successfully par new generation total 261120K, used 192941K [0x0000000080000000, 0x0000000091b50000, 0x00000000a9990000) eden space 232128K, 83% used [0x0000000080000000, 0x000000008bc6b410, 0x000000008e2b0000) from space 28992K, 0% used [0x000000008e2b0000, 0x000000008e2b0000, 0x000000008ff00000) to space 28992K, 0% used [0x000000008ff00000, 0x000000008ff00000, 0x0000000091b50000) concurrent mark-sweep generation total 579960K, used 293996K [0x00000000a9990000, 0x00000000ccfee000, 0x0000000100000000) Metaspace used 373154K, capacity 388822K, committed 394296K, reserved 1388544K class space used 48366K, capacity 54385K, committed 56128K, reserved 1048576K -XX:CICompilerCount=2 -XX:ErrorFile=/home/yuya-hirooka/java_error_in_idea_%p.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/yuya-hirooka/java_error_in_idea_.hprof -XX:InitialHeapSize=134217728 -XX:MaxHeapSize=2147483648 -XX:MaxNewSize=697892864 -XX:MaxTenuringThreshold=6 -XX:MinHeapDeltaBytes=196608 -XX:NewSize=44695552 -XX:NonNMethodCodeHeapSize=5825164 -XX:NonProfiledCodeHeapSize=122916538 -XX:OldSize=89522176 -XX:-OmitStackTraceInFastThrow -XX:ProfiledCodeHeapSize=122916538 -XX:ReservedCodeCacheSize=251658240 -XX:+SegmentedCodeCache -XX:SoftRefLRUPolicyMSPerMB=50 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseFastUnorderedTimeStamps
コマンドの一覧
jcmdで使えるコマンドには以下のようなものがあります。
(※IntteliJのプロセスに対するリストなので、完璧なリストではないかも知れません)
| コマンド名 | 説明 | インパクト |
|---|---|---|
| Compiler.CodeHeap_Analytics | コード・ヒープ(JITコンパイルされたネイティブコードとスペースマネジメントに必要な関数のストレージ)の分析結果を出力する | 低:ヒープサイズとコンテントに影響される |
| Compiler.codecache | コード・ヒープのキャッシュのレイアウトとバインドの情報を出力 | 低 |
| Compiler.codelist | コード・ヒープのキャッシュに保存されているコンパイルされた行きているメソッド | 中 |
| Compiler.directives_[add | remove | clear | print])|コンパイラー・ディレクティブ(JITコンパイラーへの指示)を追加(add)、最後に追加された指示の削除(remove)、すべての指示の削除(clear)、出力(print)。Json形式のファイルを引数に与える|低 |
| Compiler.queue | コンパイルのキューに積まれたメソッドの出力 | 低 |
| GC.class_histogram | ヒープの使用率の統計情報を出力 | 高:ヒープサイズとコンテントに影響される |
| GC.class_stats | Javaクラスのメタデータに関する統計情報を出力 | 高:ヒープサイズとコンテントに影響される |
| GC.finalizer_info | ファイナライザーのキューに関する情報を取得 | 中 |
| GC.heap_dump | HPROFフォーマットのJavaのヒープダンプを取得する | 高:ヒープサイズとコンテントに影響される。-allフラグが指定されない場合はフルGCがリクエストされる |
| GC.heap_info | ヒープサイズ、利用率などのヒープに関する一般的な情報を出力する。 | 中 |
| GC.run | java.lang.System.gc()を実行 |
中 |
| GC.run_finalization | java.lang.System.runFinalization()を実行 |
中:コンテントによって影響される |
| JFR.check | 記録中のJFRの記録をチェックする | 低 |
| JFR.configure | JFRの設定を行なう | 低 |
| JFR.dump | JFRの記録をファイルに出力する。<key>=<value>の形式でオプションを指定する。 |
低 |
| JFR.start | JFRの記録を開始する | 低〜高:レコードのないようによって影響される |
| JFR.stop | JFRの記録を停止する | 低 |
| JVMTI.agent_load | JVMTI(JVM Tool Interface。開発ツールや監視ツールで使用されるインターフェース)のネイティブエージェントをロードする | 低 |
| JVMTI.data_dump | JVMTIに対するデータダンプのリクエスト | 高 |
| ManagementAgent.start | リモートマネジメントエージェントをスタートする。 | 低:影響なし |
| ManagementAgent.start_local | ローカルのマネジメントエージェントをスタートする | 低:影響なし |
| ManagementAgent.status | マネジメントエージェントのステータスを出力 | 低:影響なし |
| ManagementAgent.stop | リモートのマネジメントエージェントを停止する | 低:影響なし |
| Thread.print | すべてのスレッドのスタックトレースを出力する | 中:スレッドの数によって影響される |
| VM.class_hierarchy | すべてのロードされているクラスのヒエラルキーをツリーで出力する | 中:ロードされているクラスの数によって影響される |
| VM.classloader_stats | すべてのクラスローダーの統計情報を出力する | 低 |
| VM.classloaders | すべてのクラスローダーをツリーで出力する | 中:クラスローダーの数によって影響される |
| VM.command_line | VMを起動する際に実行されたコマンドラインを出力する | 低 |
| VM.dynlibs | ロードされたダイナミクなライブラリーを出力する | 低 |
| VM.events | VMのイベントログを出力する | 低 |
| VM.flags | 現在利用されているVMのフラグを出力する | 低 |
| VM.info | VMの環境とステータスを出力する | 低 |
| VM.log | ログ、ログの設定を出力する | 低:影響なし |
| VM.metaspace | メタスペースに関する統計情報を出力する | 中:ロードされているクラスの数によって影響される |
| VM.native_memory | ネイティブメモリの使用率を出力する | 中 |
| VM.print_touched_methods | JVMのライフタイムで一度も触れれていないメソッドを出力する。-XX:+LogTouchedMethodsを有効化する必要がある |
中 |
| VM.set_flag | VMのオプションをセットする | 低 |
| VM.stringtable | Stringテーブルをダンプする | 中:コンテントによって影響される |
| VM.symboltable | シンボルテーブルをダンプする | 中:コンテントによって影響される |
| VM.system_properties | システムプロパティを出力する | 低 |
| VM.version | VMのバージョンを出力する | 低 |
| VM.uptime | VMの起動時間を出力する | 低 |
参考資料
KtorとKoinの組み合わでWebAPIを作る
はじめに
KotlinでWeb開発するときに、Springが選ばれることが多いと思うのですが、個人的な思いとしてはKotlin由来のライブラリーやフレームワークをなるべく使いたいという気持ちがあります。
KotlinでそのへんをやるにはKtorとWebフレームワークとKoinというDIコンテナを組み合わせて使うのが1つの大きな選択肢となると思います。KoinはKtorのサポートも行ってそうだったのでプロジェクトを作って簡単なWebアプリを作るまでをやってみようかと思います。
やってみる
環境
$ uname -srvmpio Linux 5.4.0-77-generic #86-Ubuntu SMP Thu Jun 17 02:35:03 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux $ lsb_release -a LSB Version: core-11.1.0ubuntu2-noarch:security-11.1.0ubuntu2-noarch Distributor ID: Ubuntu Description: Ubuntu 20.04.2 LTS Release: 20.04 Codename: focal $ java --version openjdk 11.0.10 2021-01-19 OpenJDK Runtime Environment 18.9 (build 11.0.10+9) OpenJDK 64-Bit Server VM 18.9 (build 11.0.10+9, mixed mode) $ mvn -v Apache Maven 3.6.3 Maven home: /usr/share/maven Java version: 11.0.10, vendor: Oracle Corporation, runtime: /home/someone/.sdkman/candidates/java/11.0.10-open Default locale: ja_JP, platform encoding: UTF-8 OS name: "linux", version: "5.4.0-77-generic", arch: "amd64", family: "unix"
プロジェクトを作成
プロジェクトはGenerate Ktor projectを用いて作成します。
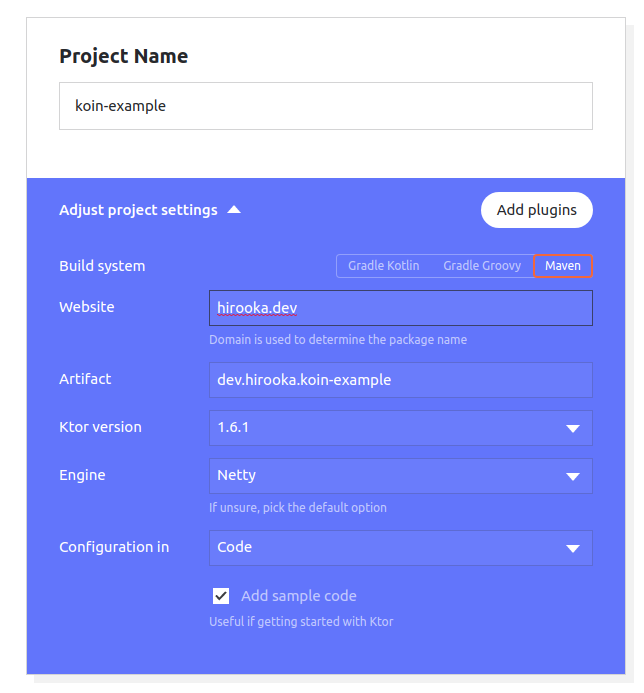

今回はMavenを使ってプロジェクトを作成します。
依存としてはRoutingだけ入れています。
Koinの依存を追加する
IDEか何かで、プロジェクトを開いてKoinの依存を追加します。
Pomに以下の依存を付け加えます。
<dependency> <groupId>io.insert-koin</groupId> <artifactId>koin-ktor</artifactId> <version>3.1.2</version> </dependency>
これで、プロジェクトの準備はできました。
諸々の設定を行なう
まずは、Ktorがapplication.confを読み込むように修正します。
Application.ktを以下のように書き換えます。
fun main(args: Array<String>) { embeddedServer(Netty, commandLineEnvironment(args)).start(wait = true) }
次にハンドラーを1つ追加します。
HelloHandler.ktを作り以下のルーティングの定期を書きます。
import io.ktor.application.* import io.ktor.response.* import io.ktor.routing.* fun Route.hello() { get("/hello") { call.respond("Hello, Koin") } }
このハンドラーをRouteingとして登録します。
再びAplication.ktに戻り以下のように修正します。
import io.ktor.application.* import io.ktor.routing.* import io.ktor.server.engine.* import io.ktor.server.netty.* fun Application.main() { install(CallLogging) routing { hello() } } fun main(args: Array<String>) { embeddedServer(Netty, commandLineEnvironment(args)).start(wait = true) }
application.confを作成してハンドラーの設定をモジュールとして読み込むようにします。
あと、今回は必要ないものもありますが、もそもろの設定もしておきます。
ktor {
deployment {
port = 8081
port = ${?APP_PORT}
}
application {
modules = [
dev.hirooka.ApplicationKt.main,
]
}
environment = "test"
environment = ${?KTOR_ENV}
}
$ mvn compile exec:java $ curl localhost:8081/hello Hello, Koin
KoinでDIする
Koinで依存を定義しDIをやってみます。
まずは、以下のようなサービスクラスとデータクラスを作成します。
data class Name(val value: String = "Moheji") interface HelloService { fun greeting(): String } class HelloServiceImlp(private val name: Name) : HelloService { override fun greeting() = "Hello, ${name.value}" }
関係性としては、HelloServiceインターフェースをHelloServiceImplが実装してNameデータクラスに依存しています。
DIの設定を記述していきます。
Application.ktを以下のように書き換えます。
import io.ktor.application.* import io.ktor.features.* import io.ktor.routing.* import io.ktor.server.engine.* import io.ktor.server.netty.* import org.koin.dsl.module import org.koin.ktor.ext.Koin fun Application.main() { install(DefaultHeaders) install(CallLogging) routing { hello() } } fun Application.koin() { install(Koin) { modules( module { single { Name() } single { HelloServiceImlp(get()) as HelloService } } ) } } fun main(args: Array<String>) { embeddedServer(Netty, commandLineEnvironment(args)).start(wait = true) }
Application.koin()でモジュールを1つ追加しKoinの依存の設定を記述しています。Application.main()モジュールで書いても問題はないのですが、設定を分けて置けるとあとから読みやすかったりするので分けました。
上記ではNameデータクラスとHelloSerivceImplクラスをそれぞれコンテナに入れています、すでにコンテナに入っているものはget()で取り出すことが可能で、HelloSerivceImplのインスタンスを生成する際のNameインスタンスをインジェクションする際に利用しています。
また、HelloSerivceImplをHelloSerivce でキャストすることで利用時にHelloSerivce方でのコンテナからの取り出しを行えます。
application.confを書き換えモジュールを読み込むように変更します。
ktor {
deployment {
port = 8081
port = ${?APP_PORT}
}
application {
modules = [
dev.hirooka.ApplicationKt.main,
dev.hirooka.ApplicationKt.koin
]
}
environment = "test"
environment = ${?KTOR_ENV}
}
それでは最後にDIコンテナに入れたHelloSerivceImplをハンドラーから利用します。
ハンドラーを以下のように書き換えます。
import io.ktor.application.* import io.ktor.response.* import io.ktor.routing.* import org.koin.ktor.ext.inject fun Route.hello() { val helloService by inject<HelloService>() get("/hello") { call.respond(helloService.greeting()) } }
コンテナからサービスを取り出す際にはinjectを利用します。
アプリケーションを起動し直して、アクセスします。
$ mvn compile exec:java $ curl localhost:8081/hello -v Hello, Moheji
一通りの使い方はこんな感じですね。
GitHub ActionsでGauge Test(Kotlin)を実行する
はじめに
仕事ではGaugeを使うことが多いのですが、GitHub Actionsを使って動かすにはどうすればいいんだろうかというところに興味が少しわきました。 そもそもGitHub Actionsをそんなに使ったことも無かったのでHello Worldも兼ねてやってみようかと思います。
やってみる
環境
Gauge(といくつかのプラグイン)は事前にインストールしています。
Gaugeのプライグインに関しては今回はgauge-javaだけでよい想定です。
$ uname -srvmpio Linux 5.4.0-77-generic #86-Ubuntu SMP Thu Jun 17 02:35:03 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux $ lsb_release -a LSB Version: core-11.1.0ubuntu2-noarch:security-11.1.0ubuntu2-noarch Distributor ID: Ubuntu Description: Ubuntu 20.04.2 LTS Release: 20.04 Codename: focal yuya-hirooka@yuya-hirooka:~/source/sleepy $ java --version openjdk 11.0.10 2021-01-19 OpenJDK Runtime Environment 18.9 (build 11.0.10+9) OpenJDK 64-Bit Server VM 18.9 (build 11.0.10+9, mixed mode) $ gauge version Gauge version: 1.3.1 Commit Hash: c76b761 Plugins ------- html-report (4.0.8) java (0.7.15) screenshot (0.0.1) xml-report (0.2.2)
プロジェクトを作成する
まずは、Gaugeのプロジェクトを作成します。
まずは、Maven Javaでプロジェクトを作成し、Kotlinで動作させるように変更します。
gauge initコマンドでプロジェクトの作成を行います。
$ mkdir gauge-kotlin $ cd gauge-kotlin/ $ gauge init java_maven Initializing template from https://github.com/getgauge/template-java-maven/releases/latest/download/java_maven.zip . Copying Gauge template java_maven to current directory ... Successfully initialized the project. Run specifications with "mvn clean test" in project root.
プロジェクトができたら、src/test/javaとspecs/example.specは消してしまって大丈夫です。
Kotlinでコードを記述できるようにするために、Pomに以下の記述を追加します。
<properties>
<kotlin.compiler.incremental>true</kotlin.compiler.incremental>
<java.version>11</java.version>
<kotlin.version>1.5.20</kotlin.version>
<kotlin.compiler.jvmTarget>${java.version}</kotlin.compiler.jvmTarget>
</properties>
<dependencies>
// もともとあった依存は省略
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-stdlib</artifactId>
<version>${kotlin.version}</version>
</dependency>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-test</artifactId>
<version>${kotlin.version}</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
// もともとあったGaugeのプラグインは省略
<plugin>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-maven-plugin</artifactId>
<version>${kotlin.version}</version>
<configuration>
<args>
<arg>-Xjsr305=strict</arg>
</args>
<jvmTarget>11</jvmTarget>
</configuration>
<executions>
<execution>
<id>compile</id>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>test-compile</id>
<phase>test-compile</phase>
<goals>
<goal>test-compile</goal>
</goals>
<configuration>
<sourceDirs>
<source>src/test/kotlin</source>
</sourceDirs>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
次にsrc/test/kotlinディレクトリを作成し、以下のクラスを作成します。
import com.thoughtworks.gauge.Step class HelloGitHubActions { @Step("Hello, GitHub Actionの文字列を出力する") fun hello(){ println("Hello, GitHub Action") } }
対応するSpecを記述します。
specs/example.specを作成し以下の記述を行います。
# Hello GitHub Actions ## GitHub Actionsに入門する * Hello, GitHub Actionの文字列を出力する
テストを実行します。
$ mvn test (省略) # Hello GitHub Actions ## GitHub Actionsに入門する Hello, GitHub Action ✔ Successfully generated html-report to => /home/yuya-hirooka/source/kotlin/gauge-kotlin/reports/html-report/index.html Specifications: 1 executed 1 passed 0 failed 0 skipped Scenarios: 1 executed 1 passed 0 failed 0 skipped Total time taken: 42ms Updates are available. Run `gauge update -c` for more info. [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 8.569 s [INFO] Finished at: 2021-07-10T15:46:47+09:00
ここまででProjectの準備は完了です。
GitHub Actionsの設定をおこなう
GitHub Actionsの概要
GitHub Actionsは、ほぼはじめてであるためまずは簡単に概要をまとめます。
GitHub Actionsは開発のライフサイクルを自動化してくれるSaaSです。
イベント駆動で、指定されたイベントが発生した際に定義してある一連のコマンドが実行されます。
GitHub Actionsを構成する要素として以下のような概念が存在します。
- Workflow
- リポジトリに追加する。一連の自動化されたプロセスです。1つ以上のJob(後述)で構成され、スケジュールかもしくは設定されたイベントの発起をトリガーに実行されます。Workflowでプロジェクトのビルド、テスト、デプロイ等を行なうことができます。
- Event
- Workflowのトリガーとなるアクティビティです。コミットのPush、Issueの作成 、プルリクなど様々なアクティビティがあります(他のアクティビティに関してはこちらをご覧ください)。
- Job
- 同一のRunnerで実行される一連のStep(後述)の集合です。Workflowが複数Jobを持つ場合はデフォルトでJobを並行で実行します。シーケンシャルにJobを実行させることも可能です。
- Step
- Job内で実行される単一のタスクです。StepはAction(後述)もしくはShellコマンドとなります。
- Action
- Stepに結合されているスタンドアローンなコマンド。Workflow内での最小の構成要素となります。独自アクションの作成が可能ですし、GitHubコミュニティによって提供されるアクションを利用することも可能です。
- Runnler
- Workflowが実行されるGitHub Action Runnerがインストールされているサーバ。自分でホストすることも可能ですし、GitHubでホストされているものを利用することも可能です。Workflowの各Jobは新しい仮想環境で実行されます。自分のRunnerをホストしたい場合はこちらを参照してください。
GitHub ActionsではWorkflowはyamlファイルで定義します。
name: learn-github-actions on: [push] jobs: check-bats-version: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - uses: actions/setup-node@v1 - run: npm install -g bats - run: bats -v
例えば上記のyamlは以下のように定義されています。
- name:Workflowの名前。Actionsタブに表示される
- on: [push]:Workflowのトリガーとなるうイベント上記の場合Pushされた際に発火される。
- jobs:Workflowを構成する一連のJobをグループ化する
- check-bats-version:Jobの名前。
- runs-on: ubuntu-latest:Jobが実行されるRunnerを定義。上記の場合Ubuntu Linuxのランナーで実行される。
- steps:
check-bats-versionJobで実行されるStepのグループ化する - uses: アクションの定義
- actions/checkout@v2:コミュニティアクションの v2 を取得するようにジョブに指示。リポジトリをランナーにチェックアウトしてアクションを実行できるようにする。
- actions/setup-node@v1:Nodeのソフトウェアパッケージをインストールしnpmコマンドを利用できるようにしている。
- run: npm install -g bats:Runnnerでコマンドを実行する。上記の場合npmでbatsをインストールしている。
- run: bats -v:Runnerでコマンドを実行する。上記の場合batsのバージョンを表示している。
ベースとなるJavaのVersionを表示するWorkflowを定義する。
一通り、まとめて早速使っていきたいと思います。
まずはリポジトリを作成して先程作成したプロジェクトをPushしておきます。
次にベースとなるWorkflowを定義します。
.github/workflows/gauge-test.yamlを作成して以下のようなyamlを記述します。
name: gauge-test on: [push] jobs: gauge-test: runs-on: ubuntu-20.04 steps: - uses: actions/checkout@v2 - uses: actions/setup-java@v2 with: distribution: 'adopt' java-version: '11' - run: java --version
上記のActionはリポジトリをチェックアウトして、Javaのセットアップを行い、Versionを表示しているだけです。
JavaのセットアップはSetup Java JDKを用いています。

上記の図のように✓のバッチが付いているAcitonはGitHubがアクションの作成者をパートナーオーガナイゼーションとして認めたものになるみたいです。
このアクションは大きく以下のようなことを行ってくれます。
Javaに関してはZulu OpenJDK、Adopt OpenJDK Hotspot、Adopt OpenJDK OpenJ9から選べるみたいで、またそのバージョンは 8、 11、15の中から選択可能なようです(その他の細かいJavaのバージョンはこちらで確認してください)。
このWorkflowをpushしGitHubリポジトリのActionsセクションを確認します。

何度かミスってしまってますが、無視してください。 最新の成功している実行を確認すると以下のように表示されます。
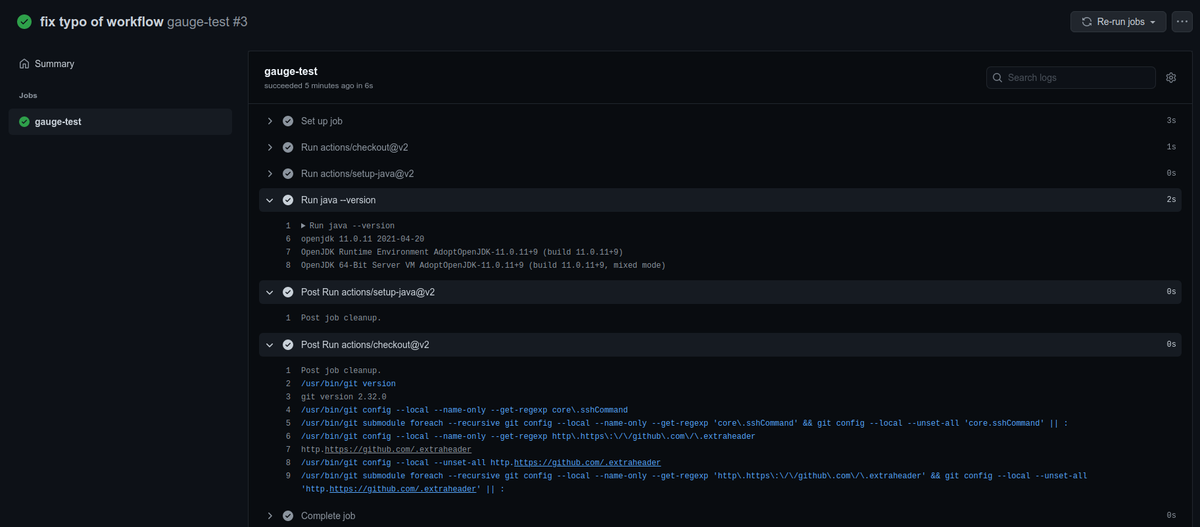
ちゃんとJavaのバージョンが表示されていますね。 クリーンの処理も走っているみたいです。
Gaugeを実行するWorkflowを定義する
ベースとなるWorkflowはできたので、Gauge Testを実行するようにWorkflowを修正します。
name: gauge-test on: [push] jobs: gauge-test: runs-on: ubuntu-20.04 steps: - uses: actions/checkout@v2 - uses: actions/setup-java@v2 with: distribution: 'adopt' java-version: '11' - run: curl -SsL https://downloads.gauge.org/stable | sh -s -- --location-[custom path] - run: gauge install java --version 0.7.15 - run: gauge version
先程のWorkflowから gaugeをインストールしてバージョンを表示するように修正しています。
pushしてActionsの実行結果をみてみます。

いい感じにできてるみたいですね。
最後に、テストを実行してみます。
name: gauge-test on: [push] jobs: gauge-test: runs-on: ubuntu-20.04 steps: - uses: actions/checkout@v2 - uses: actions/setup-java@v2 with: distribution: 'adopt' java-version: '11' - run: curl -SsL https://downloads.gauge.org/stable | sh -s -- --location-[custom path] - run: gauge install java --version 0.7.15 - run: gauge version - run: mvn test
pushしてActionsの実行結果をみてみます。

テストの実行まで行えましたね。
Skaffoldを用いてローカルでk8sにデプロイするJavaアプリの開発を行なう
はじめに
最近身の回りでSkaffoldという名前をよく聞くようになりまして、ちょっと気になって調べたら面白そうだったし、今後使っていきそうな雰囲気を感じたので、ちょっとさわっておこうかと思います。
Skaffoldとは?
Skaffoldはk8sネイティブなアプリケーションの開発をサポートしてくれるコマンドラインツールです。
k8sに対するBuild、Push、Deploy等をサポートしてくれます。
大まかには以下のような機能や特徴があります。
- ローカルでの開発において、のソースコードの変更を検知して、自動でBuild、Push、Deployまでのサポート。
- ローカルの開発において、ログに対するサポートとポートフォワードのサポート
git cloneとskaffold runの実行で様々な環境でアプリを動作させることが可能- Skaffoldのprofile, local user config, environment variables, flags などの機能を使って環境ごとの設定を組み込むことが可能
skaffold renderコマンドを用いてKubernetesマニフェストのテンプレートをレンダリングすることによって、GitOpsワークフローをサポート- Clusterは無くクライアント再度のみで独立している
skaffold.yamlファイルによって宣言的で、プラガブルな設定が可能
Skaffold自体はCI/CDにおけるワークフローのサポートも行っているようですが、今回のこのブログではローカルでのアプリケーション開発におけるいくつかの機能を試してみたいと思います。
また、今回はJavaアプリケーションで開発を行ってみようと思います。
使ってみる
動作環境
ローカルのクラスタはMinikube(Docker Drive)を用いて構築します。
$ uname -srvmpio Linux 5.4.0-77-generic #86-Ubuntu SMP Thu Jun 17 02:35:03 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux $ lsb_release -a LSB Version: core-11.1.0ubuntu2-noarch:security-11.1.0ubuntu2-noarch Distributor ID: Ubuntu Description: Ubuntu 20.04.2 LTS Release: 20.04 $ minikube version minikube version: v1.21.0 commit: 76d74191d82c47883dc7e1319ef7cebd3e00ee11 $ kubectl version -o yaml clientVersion: buildDate: "2021-03-18T01:10:43Z" compiler: gc gitCommit: 6b1d87acf3c8253c123756b9e61dac642678305f gitTreeState: clean gitVersion: v1.20.5 goVersion: go1.15.8 major: "1" minor: "20" platform: linux/amd64 serverVersion: buildDate: "2021-05-12T12:32:49Z" compiler: gc gitCommit: 132a687512d7fb058d0f5890f07d4121b3f0a2e2 gitTreeState: clean gitVersion: v1.20.7 goVersion: go1.15.12 major: "1" minor: "20" platform: linux/amd64
Skaffoldのインストール
Skaffoldをインストールするためには以下のコマンドを叩きます。
$ curl -Lo skaffold https://storage.googleapis.com/skaffold/releases/latest/skaffold-linux-amd64 && \ sudo install skaffold /usr/local/bin/ $ skaffold version v1.27.0
その他、MacやWindows、Dockerでのインストールはこちらをご確認ください。
サンプルアプリを作成しておく
Skaffoldを使ってデプロイやディバグなどの機能を試すために開発対象となるアプリを作っておきます。
特に深い意図はないのですがSpringを使ってやろうかと思います。
Spring Initializrで以下の設定でアプリを作成します。

依存はWebだけを追加してます。
Skaffoldプロジェクトを初期化する
ダウンロードしてきたプロジェクトを解凍して、プロジェクトのルートに移動し以下のコマンドを実行します。
Skaffoldプロジェクトを初期化するには、skaffold initコマンドを用います。
skaffold initコマンドは実行するとプロジェクトをスキャンし、以下のようなファイルを見つけるとその構成に合わせた設定を行ってくれます。
ちなみに500MB以上のファイルは無視されるようです。
例えば、こんかいのケースではいくつかの選択肢を提示してくれます。
$ skaffold init --generate-manifests ? Select port to forward for pom-xml-image (leave blank for none): 8080
--XXenableJibInitフラグや--XXenableBuildpacksInitフラグを使えば、それぞれJibやBuildpacksを用いた構成を作ることも可能なようです。
--generate-manifestsフラグはマニフェストの生成まで行ってもらうために使用しています。このフラグを使用しない場合は自分で作成したdeployment.yamlを用いることになります。
今回の場合はpom.xmlのみが検知され、Buildpackを用いた設定がされます。
$ skaffold init --generate-manifests
? Select port to forward for pom-xml-image (leave blank for none): 8080
adding manifest path deployment.yaml for image pom-xml-image
apiVersion: skaffold/v2beta18
kind: Config
metadata:
name: skaffold-sample
build:
artifacts:
- image: pom-xml-image
buildpacks:
builder: gcr.io/buildpacks/builder:v1
deploy:
kubectl:
manifests:
- deployment.yaml
portForward:
- resourceType: service
resourceName: pom-xml-image
port: 8080
deployment.yaml - apiVersion: v1
kind: Service
metadata:
name: pom-xml-image
labels:
app: pom-xml-image
spec:
ports:
- port: 8080
protocol: TCP
clusterIP: None
selector:
app: pom-xml-image
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: pom-xml-image
labels:
app: pom-xml-image
spec:
replicas: 1
selector:
matchLabels:
app: pom-xml-image
template:
metadata:
labels:
app: pom-xml-image
spec:
containers:
- name: pom-xml-image
image: pom-xml-image
? Do you want to write this configuration, along with the generated k8s manifests, to skaffold.yaml? Yes
Generated manifest deployment.yaml was written
Configuration skaffold.yaml was written
You can now run [skaffold build] to build the artifacts
or [skaffold run] to build and deploy
or [skaffold dev] to enter development mode, with auto-redeploy
skaffold.yamlは以下のようになります。
apiVersion: skaffold/v2beta18 kind: Config metadata: name: skaffold-sample build: artifacts: - image: pom-xml-image buildpacks: builder: gcr.io/buildpacks/builder:v1 deploy: kubectl: manifests: - deployment.yaml portForward: - resourceType: service resourceName: pom-xml-image port: 8080
上記のskaffold.yamlではビルドやデプロイ、ポートフォワードの設定が行われています。
その他、ここで使われていない項目や設定の説明はこちらをご覧ください。
次に進む前にイメージの名前がpom-xml-sampleだとあまりにもあまりになので以下のように書き換えておきます。
また、Buildkitを有効にしておきます。
apiVersion: skaffold/v2beta18 kind: Config metadata: name: skaffold-sample build: artifacts: - image: spring-app buildpacks: builder: gcr.io/buildpacks/builder:v1 deploy: kubectl: manifests: - deployment.yaml portForward: - resourceType: service resourceName: pom-xml-image port: 8080
作成されたk8sのマニフェストのpom-xml-sampleの部分もspring-appに書き換えておきます。
apiVersion: v1 kind: Service metadata: name: spring-app labels: app: spring-app spec: ports: - port: 8080 protocol: TCP clusterIP: None selector: app: spring-app --- apiVersion: apps/v1 kind: Deployment metadata: name: spring-app labels: app: spring-app spec: replicas: 1 selector: matchLabels: app: spring-app template: metadata: labels: app: spring-app spec: containers: - name: spring-app image: spring-app
devモードをで開発を行なう
前述したとおり、Skaffoldはローカルでの開発に置いてソースコードの変更を検知して、自動でBuild、Push、Deployまでのサポートまでをサポートしてくれます。
devモードで起動するとその機能が利用可能で、以下のコマンドでdevモードで起動します。
$ skaffold dev (省略) Starting test... Tags used in deployment: - spring-app -> spring-app:e0b79f2a42356a8de0ba7b3da0f0f74903c0d9b99ddf1db39ed36a872a90d577 Starting deploy... - service/spring-app created - deployment.apps/spring-app created Waiting for deployments to stabilize... - deployment/spring-app is ready. Deployments stabilized in 1.129 second Press Ctrl+C to exit Watching for changes... [spring-app] [spring-app] . ____ _ __ _ _ [spring-app] /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ [spring-app] ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ [spring-app] \\/ ___)| |_)| | | | | || (_| | ) ) ) ) [spring-app] ' |____| .__|_| |_|_| |_\__, | / / / / [spring-app] =========|_|==============|___/=/_/_/_/ [spring-app] :: Spring Boot :: (v2.5.2) [spring-app] [spring-app] 2021-07-08 17:17:30.213 INFO 20 --- [ main] d.h.s.SkaffoldSampleApplication : Starting SkaffoldSampleApplication v0.0.1-SNAPSHOT using Java 11.0.11 on spring-app-6d5b5c74c4-2q6xs with PID 20 (/workspace/target/skaffold-sample-0.0.1-SNAPSHOT.jar started by cnb in /workspace) [spring-app] 2021-07-08 17:17:30.215 INFO 20 --- [ main] d.h.s.SkaffoldSampleApplication : No active profile set, falling back to default profiles: default [spring-app] 2021-07-08 17:17:31.073 INFO 20 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http) [spring-app] 2021-07-08 17:17:31.085 INFO 20 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat] [spring-app] 2021-07-08 17:17:31.086 INFO 20 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/9.0.48] [spring-app] 2021-07-08 17:17:31.156 INFO 20 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext [spring-app] 2021-07-08 17:17:31.157 INFO 20 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 880 ms [spring-app] 2021-07-08 17:17:31.683 INFO 20 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path '' [spring-app] 2021-07-08 17:17:31.691 INFO 20 --- [ main] d.h.s.SkaffoldSampleApplication : Started SkaffoldSampleApplication in 2.022 seconds (JVM running for 2.444)
コマンドを実行するとビルドが始まり少し待つとKubernetes上にデプロイされます。
また、devモードで起動するとローカルマシンへのポートフォワードも自動的に行ってくれます
ここまででServiceとDeploymentがローカルのMinikubeで作ったクラスタに作成されリソースが作られている状態でかつホストマシンへのポートフォワードまで行われています。
$ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 7d3h spring-app ClusterIP None <none> 8080/TCP 4m48s $ kubectl get deploy NAME READY UP-TO-DATE AVAILABLE AGE spring-app 1/1 1 1 5m17s
8080ポートフォワードされているのでcURLでアクセスしてみます。
$ curl localhost:8080
{"timestamp":"2021-07-08T17:28:57.961+00:00","status":404,"error":"Not Found","path":"/"}
現状はコントローラーを作成していないので404が返ってきます。
以下のクラスを作成してコントローラーを1つ作ってみます。
@RestController public class SampleController { @GetMapping("/") public String helle(){ return "Hello, Skaffold"; } }
コードを修正すると自動でビルドが走りクラスターにデプロイされます。
再度、cURLでアクセスすると今度はHello, Skaffoldの文字列が返ってきます。
$ curl localhost:8080 Hello, Skaffold
debugモードで起動して、IntelliJを用いてDebugする
Skaffoldのdebugモードはdevモードと同じように動作しますが、debug用のPodが立ち上がりlanguage runtimeに応じたdebug用のポートがホストにポートフォワードされます。
Javaの場合はJDWPを用いてdebugが可能となるようです。
ここで、debug自動デプロイ機能が無効になるので注意が必要です。
以下のコマンドでdebugモードで起動します。
$ skaffold debug (省略) [spring-app] Picked up JAVA_TOOL_OPTIONS: -agentlib:jdwp=transport=dt_socket,server=y,address=5005,suspend=n,quiet=y (省略) Port forwarding pod/spring-app-7b74d66d9-42wns in namespace default, remote port 5005 -> 127.0.0.1:5005
ログに出力されているように出力されJWDPのポートが5005で公開されてるのがわかります。
InteliJからリモートdebug用のプロセスに接続します。
Run/Debug Configurationを開き左上の+ボタンからRemote JVM Debugを選択します。

基本はデフォルトのままの設定で大丈夫ですが、名前の部分だけspring-appにしておきます。
Applyを押してIntelliJをDebug実行をすると起動します。
先程のコントローラーにブレークポイントを置いておきます。

この状態で再度cURLでリクエストを投げると置いたブレークポイントで停止することが確認できます。
